

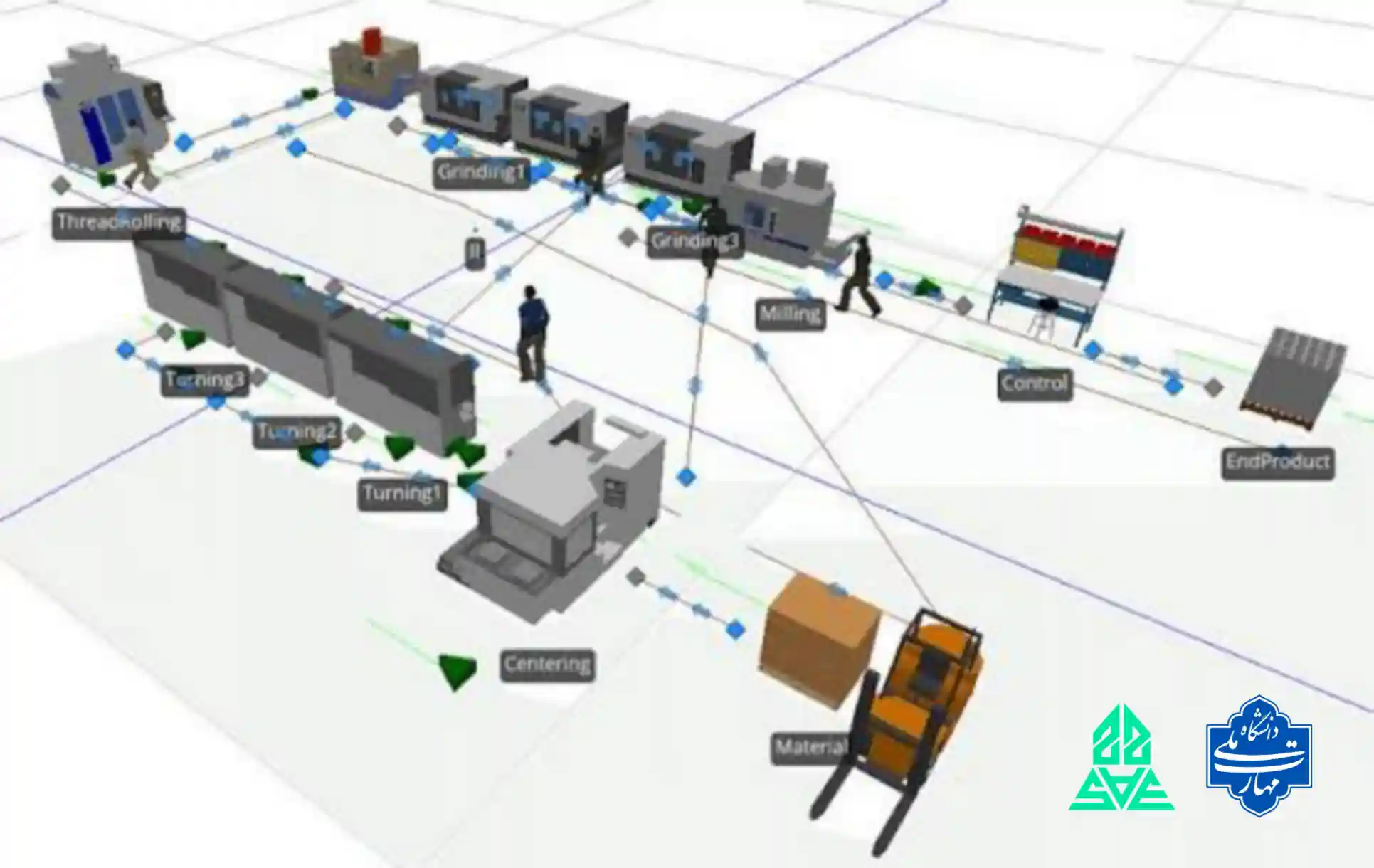
جزوه درس شبیه سازی سیستم های گسسته پیش آمد
فهرست مطالب
مقدمهای بر درس شبیهسازی سیستمهای گسسته پیشامد (Discrete Event Simulation)
این مجموعه آموزشی، بر اساس جزوه ارزشمند دکتر سید حسن حسینی، استاد محترم دانشکده ملی مهارت امام محمد باقر (ع) ساری (وابسته به دانشگاه ملی مهارت استان مازندران)، تهیه و گسترش یافته است. هدف از این کار، ارائه توضیحات سادهتر، مثالهای بیشتر، بازنویسی مطالب به زبان قابل فهم برای دانشجویان مبتدی و تکمیل بخشهایی است که ممکن است نیاز به جزئیات اضافی داشته باشد.
درس شبیهسازی سیستمهای گسسته پیشامد یکی از دروس مهم در رشتههای مهندسی کامپیوتر، نرمافزار و صنایع است. در این درس یاد میگیریم چطور سیستمهای واقعی دنیا (مثل بانک، بیمارستان، کارخانه یا شبکه کامپیوتری) که تغییراتشان به صورت ناگهانی و در لحظات خاص (رویدادها) اتفاق میافتد، را مدل کنیم و با کامپیوتر شبیهسازی کنیم تا بدون هزینه واقعی، رفتار سیستم را پیشبینی کنیم، مشکلات را پیدا کنیم و راهحلهای بهینه پیشنهاد دهیم.
این مطالب به صورت مبحث به مبحث، با زبان ساده و مثالهای روزمره توضیح داده شده تا حتی دانشجویانی که تازه با این درس آشنا شدند، به راحتی بفهمند. منبع اصلی تمام مطالب، جزوه دکتر سید حسن حسینی است و هرگونه گسترش یا مثال اضافی با ذکر منبع اصلی آورده شده.
در پایان این صفحه، تعدادی ویدیو از سایر دوره ها قرار گرفته که پیشنهاد می شود در صورت نداشتن وقت کافی یا نیاز به مثال های بیشتر و حل مرحله به مرحله، حتما ویدیو ها را مشاهده فرمایید.
درمورد جزوه درس بازی سازی با یونیتی در رشته نرم افزار کامپیوتر بخوانید.
مقدمهای بر شبیهسازی سیستمهای گسسته پیشامد
تعریف شبیهسازی (توضیح تخصصی)
شبیهسازی، تکنیکی است برای تقلید از عملکرد یک سیستم یا فرآیند واقعی دنیا در طول زمان، به منظور پیشبینی تأثیر تغییرات در سیستمهای موجود یا طراحی سیستمهای جدید بدون نیاز به پیادهسازی واقعی آنها.
در زمینه شبیهسازی سیستمهای گسسته پیشامد (Discrete Event Simulation – DES)، تمرکز روی سیستمهایی است که حالت آنها فقط در لحظات خاص (رویدادها یا پیشامدها) تغییر میکند، نه به صورت پیوسته. مثلاً ورود مشتری به بانک (رویداد ورود)، شروع خدمت (رویداد خدمت) و خروج مشتری (رویداد خروج). این تعریف بر اساس منابع استاندارد مانند کتاب بنکس و کارسن (ترجمه محلوجی، انتشارات دانشگاه صنعتی شریف) و آموزشهای فرادرس است، که شبیهسازی را ابزاری قدرتمند در تحقیق عملیات میدانند.
به زبان ساده: تصور کن میخوای ببینی اگر به یک بانک یک باجه بیشتر اضافه کنی، صف مشتریان کمتر میشه یا نه. به جای اینکه واقعاً باجه بسازی و صبر کنی ببین چی میشه (که هزینه و زمان زیادی میبره)، یک مدل کامپیوتری از بانک میسازی و با کامپیوتر “بازی” میکنی تا ببینی چی پیش میآد. شبیهسازی دقیقاً همین کار رو میکنه: دنیای واقعی رو تقلید میکنه تا بدون ریسک واقعی، آزمایش کنی!
مزایای شبیهسازی (توضیح تخصصی)
بر اساس منابع معتبر (کتاب بنکس و کارسن، و مقالات مرتبط در سایتهای آموزشی مانند pwut.ac.ir و فرادرس):
- صرفهجویی در زمان و هزینه: آزمایش تغییرات روی مدل کامپیوتری خیلی سریعتر و ارزانتر از دنیای واقعی است.
- کاهش ریسک و خطر: میتوان سناریوهای خطرناک (مثل جنگ یا حوادث) را بدون خطر واقعی تست کرد.
- امکان اصلاح و بهبود ساختاری: سیستم را بارها تغییر داد و بهترین حالت را پیدا کرد.
- بهکارگیری متعدد و تکرارپذیر: مدل را هزاران بار اجرا کرد تا نتایج دقیقتری گرفت.
- تحلیل با دادههای تقریبی: حتی اگر دادهها دقیق نباشند، شبیهسازی مفید است (برخلاف روشهای تحلیلی که نیاز به داده دقیق دارند).
- پیادهسازی سادهتر نسبت به روشهای تحلیلی: برای سیستمهای پیچیده که حل ریاضی ندارند، شبیهسازی راهحل عملی است.
به زبان ساده: شبیهسازی مثل یک “بازی ویدیویی” از دنیای واقعی است! زمان و پولت رو هدر نمیدی، خطر نداره (مثل تست بمب بدون انفجار واقعی)، میتونی صد بار امتحان کنی تا بهترین راه رو پیدا کنی، و حتی با اطلاعات ناقص هم کار میکنه. خیلی بهتر از حل معادلات پیچیده ریاضی که گاهی اصلاً ممکن نیست!
معایب شبیهسازی (توضیح تخصصی)
(از همان منابع استاندارد مانند کتاب محلوجی و بحثهای اشمید و تیلور):
- پر هزینه بودن در مدلهای پیچیده: ساخت مدل دقیق، جمعآوری داده و اجرای متعدد نیاز به زمان، نیروی متخصص و کامپیوتر قدرتمند دارد.
- امکان نادیده گرفتن عوامل مهم: اگر مدل همه جزئیات واقعی را پوشش ندهد، نتایج غلط میشود.
- نیاز به اجرای فراوان: برای نتایج قابل اعتماد، باید مدل را هزاران بار اجرا کرد (به دلیل تصادفی بودن بسیاری سیستمها).
- وابستگی به روشهای ریاضی و آماری: تولید اعداد تصادفی و تحلیل خروجیها نیاز به دانش تخصصی دارد.
به زبان ساده: هیچ چیزی کامل نیست! گاهی ساخت مدل خودش گرون و زمانبر میشه، ممکنه چیزی مهم رو فراموش کنی و نتیجه اشتباه بگیری، باید کلی بار اجراش کنی تا مطمئن شی، و نیاز به دانش ریاضی داری. اما معمولاً مزایاش بیشتر از معایبشه.
زمینههای کاربرد شبیهسازی (توضیح تخصصی)
شبیهسازی گسسته پیشامد در سیستمهای واقعی که تغییرات ناگهانی دارند، کاربرد گستردهای دارد (بر اساس مثالهای کتاب بنکس و منابع ایرانی):
- فرودگاهها: کنترل ترافیک هوایی، مدیریت ظرفیت باند، زمانبندی چراغهای راهنمایی، نگهداری تجهیزات.
- ترافیک شهری و جادهای: بهینهسازی زمان چراغهای راهنمایی، پیشبینی ترافیک.
- نظامی: شبیهسازی جنگها، استراتژیها و مانورها.
- اقتصادی کلان: مدلسازی بازارها، زنجیره تأمین و سیستمهای تولیدی.
- سایر: بیمارستانها (مدیریت صف بیماران)، بانکها، کارخانهها (خط تولید)، شبکههای کامپیوتری.
به زبان ساده: هر جایی که “صف” یا “رویداد ناگهانی” داری، شبیهسازی کمک میکنه! مثلاً در فرودگاه ببین چطور هواپیماها بدون تصادف فرود بیان، یا در شهر زمان چراغ قرمز رو تنظیم کن تا ترافیک کمتر بشه، یا حتی جنگ رو بدون شلیک گلوله تست کن. خیلی جاها مثل بیمارستان، کارخانه یا اقتصاد بزرگ استفاده میشه.
انواع شبیهسازی
شبیهسازی سیستمها عمدتاً به دو نوع اصلی تقسیم میشود (بر اساس منابع استاندارد مانند کتاب «شبیهسازی سیستمهای گسسته-پیشامد» نوشته جری بنکس و ترجمه هاشم محلوجی، و آموزشهای فرادرس و ویکیپدیا):
۱- شبیهسازی گسسته (Discrete Simulation)
توضیح تخصصی: در این نوع، متغیرهای حالت سیستم فقط در لحظات خاص (زمان وقوع رویدادها یا پیشامدها) تغییر میکنند. تغییرات به صورت ناگهانی و در نقاط گسسته زمانی اتفاق میافتد. تمرکز اصلی درس ما روی شبیهسازی گسسته پیشامد (Discrete Event Simulation – DES) است، که سیستم را به عنوان توالی رویدادها مدل میکند (مثل ورود مشتری، شروع خدمت، خروج).
به زبان ساده: تغییرات سیستم “با فاصله” و فقط در لحظههای خاص اتفاق میافتد، مثل ورود یک مشتری جدید به صف بانک که ناگهان تعداد افراد در صف را تغییر میدهد. بین رویدادها، هیچ تغییری نیست!
۲- شبیهسازی پیوسته (Continuous Simulation)
توضیح تخصصی: متغیرهای حالت سیستم در هر لحظه زمانی به صورت پیوسته تغییر میکنند و معمولاً با معادلات دیفرانسیل مدلسازی میشوند. مقادیری مثل زمان، فاصله، سرعت یا دما که میتوانند هر عددی در یک بازه بگیرند.
به زبان ساده: تغییرات سیستم “بیفاصله” و مداوم است، مثل پر شدن آرام یک مخزن آب که سطح آب هر لحظه کمی بیشتر میشود، یا تغییر دما در یک اتاق.
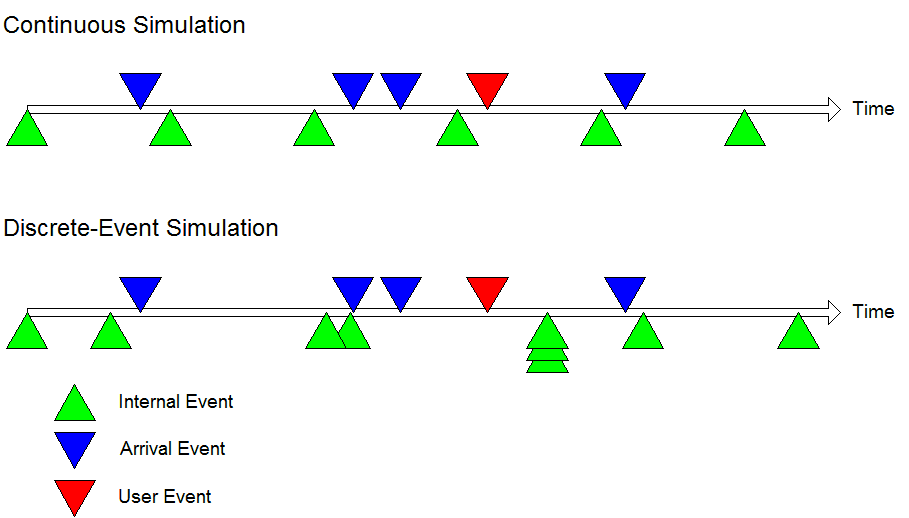
(مثال شبیهسازی گسسته: مدل صف مشتریان در بانک)

(مثال شبیهسازی پیوسته: تغییرات مداوم در یک سیستم فیزیکی)
سیستم، محدوده عمل و محیط سیستم
در شبیهسازی، درک مفهوم سیستم و مرزهای آن خیلی مهم است (بر اساس تعاریف استاندارد در مهندسی سیستمها و کتابهای شبیهسازی مانند بنکس و کارسن، ترجمه محلوجی، و منابع تحقیق عملیات).
تعریف سیستم (توضیح تخصصی)
سیستم، مجموعهای از اجزای مرتبط و وابسته به یکدیگر است که برای رسیدن به یک هدف مشخص، با هم کار میکنند. اجزا از طریق روابط متقابل به هم پیوستهاند و رفتار کلی سیستم از تعامل این اجزا ناشی میشود.
به زبان ساده: سیستم مثل یک تیم فوتبال است: بازیکنان (اجزا) با قوانین و روابط خاص (پاس دادن، موقعیتها) با هم کار میکنند تا گل بزنند (هدف مشترک). اگر یکی نباشد یا خوب کار نکند، کل تیم دچار مشکل میشود!
(تصویر بالا: دیاگرام ساده سیستم باز با ورودیها، خروجیها و محیط خارجی)
محدوده عمل سیستم (System Boundary)
محدوده یا مرز سیستم، خطی خیالی است که مشخص میکند چه چیزهایی داخل سیستم هستند و چه چیزهایی خارج. این مرز کمک میکند تمرکز کنیم روی بخشهای قابل کنترل.
به زبان ساده: مثل حصار دور یک خانه: داخل حصار (سیستم) چیزهایی است که خودت کنترل میکنی، خارج از آن (محیط) چیزهایی که نمیتوانی مستقیم کنترل کنی.
محیط سیستم (Environment)
عوامل خارجی که خارج از کنترل سیستم هستند، اما میتوانند روی عملکرد آن تأثیر بگذارند. سیستم معمولاً به تغییرات محیط حساس است (مثل تغییرات اقتصادی یا آب و هوا).
به زبان ساده: محیط مثل هوای بیرون خانه است: باران ببارد، ممکن است داخل خانه نم بدهد، حتی اگر درها بسته باشد!
نکته مهم در تعریف سیستم
اگر عوامل خارجی خیلی روی سیستم تأثیر بگذارند، میتوانیم مرز سیستم را گسترش دهیم و آن عوامل را به عنوان ورودی داخل مدل بیاوریم. مثال: در یک کارخانه تولیدی، سفارش مشتریان و مواد اولیه خام (عرضه بازار) خارج از کنترل مستقیم کارخانه هستند، اما تأثیر زیادی دارند. پس در مدل شبیهسازی، آنها را به عنوان ورودی در نظر میگیریم تا رفتار واقعی سیستم را بهتر پیشبینی کنیم.
به زبان ساده: اگر چیزی بیرون خیلی اذیتت میکنه، میتونی حصار رو بزرگتر کنی و اون رو داخل بیاری! مثلاً کارخانه سفارشهای مشتری رو “ورودی” حساب میکنه تا ببینه چطور تولید رو تنظیم کنه.
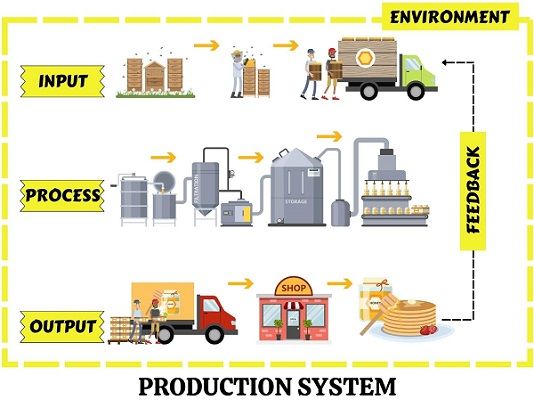
(تصویر بالا: مثال سیستم کارخانه با ورودیها (مواد، سفارش) و خروجیها (محصولات) در محیط خارجی)
اجزای سیستم در شبیهسازی گسسته پیشامد
در شبیهسازی گسسته پیشامد، سیستم از اجزای خاصی تشکیل شده که درک آنها برای مدلسازی ضروری است (بر اساس تعاریف استاندارد در کتاب جری بنکس و جان کارسن، ترجمه هاشم محلوجی، و منابع آموزشی مانند Fiveable و MoreSteam).
(تصاویر بالا: دیاگرام اجزای اصلی شبیهسازی گسسته مانند موجودیتها، مشخصهها، فعالیتها، رویدادها و متغیرهای حالت)
۱- نهاد (موجودیت – Entity)
توضیح تخصصی: عناصر موقتی و پویا که وارد سیستم میشوند، در آن جریان دارند و در نهایت خارج میشوند. موجودیتها دارای ابعاد (attributes) هستند و معمولاً منبع اصلی تغییرات در سیستماند.
به زبان ساده: موجودیتها مثل “مشتریان” در یک بانک هستند – وارد میشوند، کارشان انجام میشود و میروند. چیزهایی که سیستم برای آنها طراحی شده!

(تصویر بالا: مثال موجودیتها در سیستم صف بانک)
۲- مشخصه (Attribute)
توضیح تخصصی: ویژگیهایی که موجودیت را توصیف میکنند و در طول شبیهسازی میتوانند تغییر کنند یا ثابت بمانند.
به زبان ساده: مثل مشخصات یک مشتری: زمان ورود، نوع خدمت مورد نیاز، یا اولویت. اینها کمک میکنند هر موجودیت را منحصر به فرد بشناسیم.
۳- فعالیت (Activity)
توضیح تخصصی: هر فعالیت نمایانگر یک دوره زمانی با طول مشخص است که سیستم در آن حالت خاصی قرار دارد (مثل زمان خدمتدهی).
به زبان ساده: فعالیت مثل “زمان صرف شده برای خدمت به یک مشتری” است – یک کار که زمان میبرد و سیستم را مشغول نگه میدارد.
۴- رویداد (Event) یا پیشامد
توضیح تخصصی: رویدادی لحظهای که وضعیت سیستم را تغییر میدهد. معمولاً شامل ورود یا خروج موجودیتهاست و متغیرهای حالت را بروز میکند.
به زبان ساده: رویداد مثل “ورود یک مشتری جدید” یا “خروج مشتری پس از خدمت” است – لحظهای که ناگهان چیزی در سیستم تغییر میکند!
۵- وضعیت سیستم (State) و متغیر حالت (State Variable)
توضیح تخصصی: وضعیت سیستم، مجموعه متغیرهای لازم برای توصیف کامل سیستم در هر لحظه است (با مقادیر عددی تخصیصیافته به مشخصهها). متغیرهای حالت، مقادیری هستند که وضعیت را نشان میدهند (مثل تعداد مشتریان در صف).
به زبان ساده: وضعیت مثل عکس فوری از سیستم در یک لحظه است: چند نفر در صف هست؟ چند باجه مشغول؟ متغیر حالت عددی است که این را نشان میدهد (مثل “تعداد = ۵”).
(تصویر بالا: دیاگرام تغییرات متغیرهای حالت در شبیهسازی گسسته)
مشخصههای ثابت و متغیر
توضیح تخصصی: مشخصهها توصیفکننده موجودیتها هستند. مقدار برخی ثابت میماند (Fixed) و برخی تغییر میکند (Variable).
به زبان ساده:
- متغیر: مثل مانده حساب بانکی یا زمان انتظار مشتری (در طول زمان تغییر میکند).
- ثابت: مثل نوع درمان خاص برای یک بیمار یا مراحل ثابت تولید یک محصول (تغییر نمیکند).
مدلسازی در شبیهسازی
تعریف مدلسازی (توضیح تخصصی)
مدلسازی، فرآیند ایجاد یک نمای سادهشده و انتزاعی از یک سیستم واقعی است، با هدف پیشبینی معیارهای عملکردی قابل اندازهگیری (مانند زمان انتظار، بهرهوری یا هزینه). این تعریف بر اساس منابع استاندارد مانند کتاب جری بنکس و جان کارسن (ترجمه هاشم محلوجی) و سایتهای آموزشی مانند MathWorks و ResearchGate است.
به زبان ساده: مدلسازی مثل ساخت یک ماکت کوچک از یک ماشین واقعی است – همه جزئیات رو نداره، اما کمک میکنه ببینی چطور کار میکنه و عملکردش چیه، بدون اینکه ماشین واقعی بسازی!
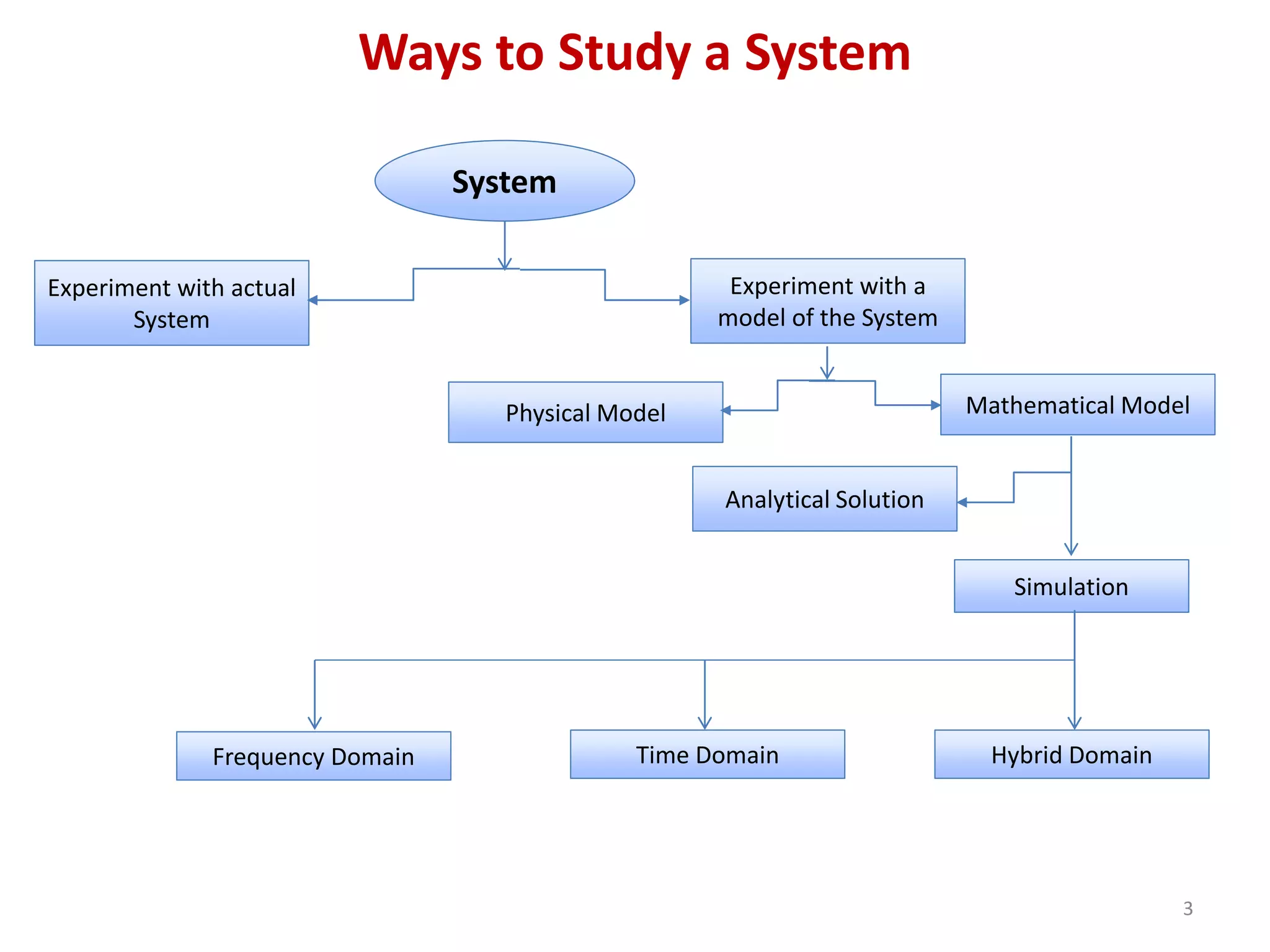

(تصاویر بالا: دیاگرام انواع مدلسازی و روشهای مطالعه سیستم)
انواع مدلسازی
توضیح تخصصی: مدلها به سه دسته اصلی تقسیم میشوند:
- فیزیکی (Physical): ماکتهای واقعی و ملموس (مثل مدل مقیاسدار یک فرودگاه).
- تحلیلی (ریاضی – Analytical): استفاده از معادلات ریاضی و حل تحلیلی (مثل مدلهای صف در تحقیق عملیات).
- کامپیوتری (Simulation): مدلهای اجرایی روی کامپیوتر، مخصوص سیستمهای پیچیده.
به زبان ساده:
- فیزیکی: مثل ساخت ماکت با چوب یا پلاستیک.
- ریاضی: حل با فرمول و معادله روی کاغذ.
- کامپیوتری: اجرا با نرمافزار روی کامپیوتر – بهترین برای سیستمهای واقعی و پیچیده!

نرمافزارهای شبیهسازی
توضیح تخصصی: پیچیدگی سیستمهای واقعی (تعداد زیاد رویدادها و متغیرها) باعث میشود از نرمافزارهای کامپیوتری استفاده کنیم. این نرمافزارها چارچوب آمادهای برای ساخت، اجرا و تحلیل مدل فراهم میکنند. مثالهای معروف: Arena، Simio، AnyLogic، ExtendSim و حتی زبانهای برنامهنویسی مثل Python (با کتابخانه SimPy).
به زبان ساده: سیستمهای واقعی خیلی شلوغ و پیچیدهاند، پس به جای کد نوشتن از صفر، از نرمافزارهای آماده استفاده میکنیم که همه چیز رو راحتتر میکنه!

(تصاویر بالا: مثالهایی از نرمافزارهای شبیهسازی گسسته مانند AnyLogic، Simio و Arena)
مزایای نرمافزارهای شبیهسازی
توضیح تخصصی: این نرمافزارها فرآیند را تسهیل میکنند در:
- پردازش ورودیها (دادههای ورودی مدل).
- ثبت و ذخیره دادهها طی اجرا.
- تولید گزارشهای خروجی (گراف، جدول و آمار).
- ایجاد اعداد تصادفی (برای مدلسازی عدم قطعیت).
- جمعآوری و اجماع دادهها در متغیرهای خروجی (برای تحلیل عملکرد).
به زبان ساده: نرمافزارها کار رو خیلی آسان میکنن: ورودیها رو راحت وارد کنی، دادهها رو خودکار ذخیره کنن، گزارش قشنگ بدن، اعداد رندوم بسازن و نتایج رو جمعبندی کنن – بدون دردسر دستی!

(تصاویر بالا: دیاگرام و فلوچارت مزایا و فرآیند شبیهسازی)
گامهای اساسی (مراحل) انجام شبیهسازی گسسته پیشامد
گامهای اساسی شبیهسازی، یک فرآیند استاندارد و مرحلهبهمرحله است که برای هر پروژه شبیهسازی دنبال میشود (بر اساس منابع معتبر مانند کتاب جری بنکس و جان کارسن «Discrete-Event System Simulation»، ترجمه هاشم محلوجی، و استانداردهای انجمن شبیهسازی مانند INFORMS و سایتهای آموزشی MathWorks و TutorialsPoint). این مراحل معمولاً ۱۰-۱۲ گام دارند، اما به صورت خلاصه به ۷-۱۰ گام اصلی تقسیم میشوند.
توضیح تخصصی: فرآیند شبیهسازی یک چرخه تکراری است که شامل تعریف مسئله، مدلسازی مفهومی، جمعآوری داده، پیادهسازی مدل کامپیوتری، اعتبارسنجی، آزمایش سناریوها و تحلیل نتایج میشود. هدف، اطمینان از اینکه مدل واقعی را دقیق نشان میدهد و نتایج قابل اعتماد هستند.

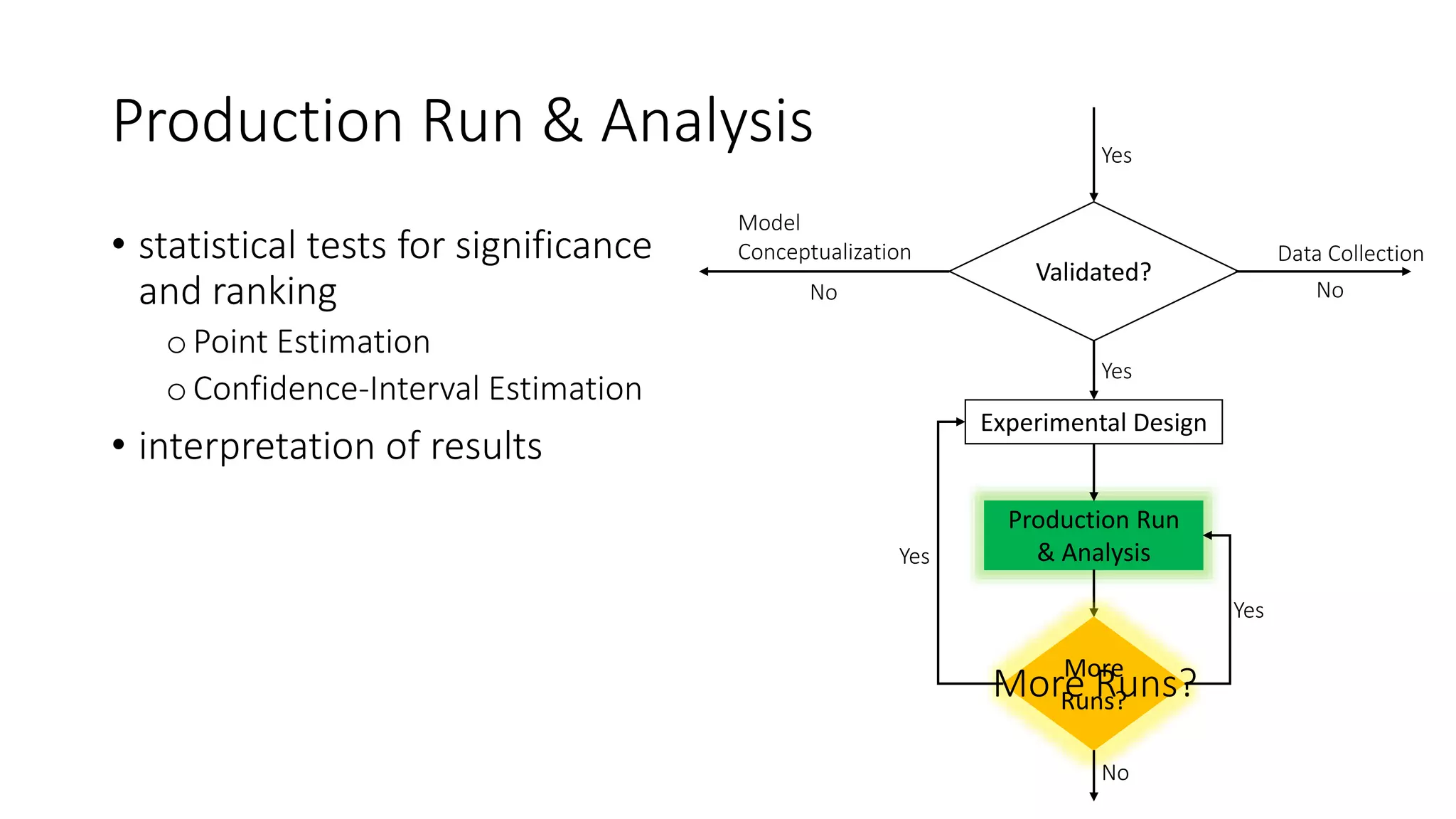
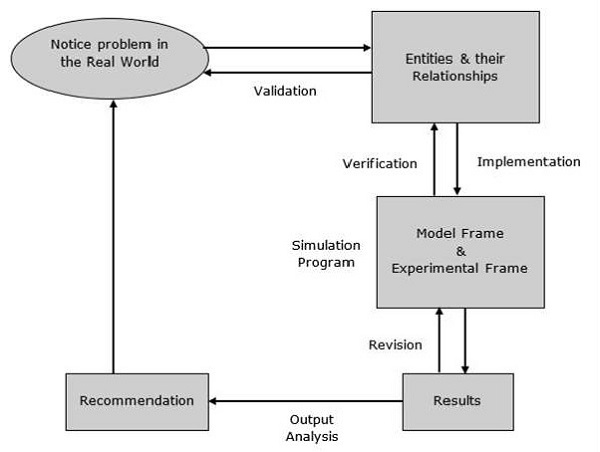
(تصاویر بالا: دیاگرامها و فلوچارتهای گامهای شبیهسازی از منابع استاندارد)
گامهای اساسی مرحله به مرحله (با مثال: کاهش مدت زمان صف انتظار در باجه بانک)
مثال مسئله: بانک میخواهد زمان متوسط انتظار مشتریان در صف را کاهش دهد (مثلاً از ۱۰ دقیقه به کمتر از ۵ دقیقه)، بدون استخدام نیروی اضافی زیاد.
به زبان ساده: شبیهسازی مثل حل یک پازل است – قدم به قدم پیش میری تا بهترین راهحل رو پیدا کنی. حالا با مثال بانک، ببین چطور کار میکنه!
۱. تعریف مسئله و اهداف (Problem Formulation): توضیح تخصصی: مشخص کردن سوال اصلی، اهداف کمی و مرز سیستم. به زبان ساده: چی میخوایم حل کنیم؟ مثال: هدف: کاهش زمان متوسط انتظار مشتریان در صف باجه بانک به کمتر از ۵ دقیقه، با تست اضافه کردن باجه یا تغییر زمانبندی.
۲. جمعآوری داده و تعریف مدل مفهومی (Data Collection & Conceptual Modeling): توضیح تخصصی: جمع دادههای واقعی (توزیع ورود، زمان خدمت) و تعریف اجزا (موجودیتها، رویدادها، متغیرها). به زبان ساده: اطلاعات واقعی رو جمع کن و سیستم رو روی کاغذ طراحی کن. مثال: اندازهگیری نرخ ورود مشتریان (مثلاً هر ۵ دقیقه یکی با توزیع پواسون) و زمان خدمت هر باجه (مثلاً توزیع نمایی با میانگین ۴ دقیقه).
۳. ساخت مدل کامپیوتری (Model Implementation): توضیح تخصصی: پیادهسازی مدل در نرمافزار (مثل Arena یا SimPy). به زبان ساده: مدل رو توی کامپیوتر بساز. مثال: ساخت مدل صف بانک با بلوکهای ورود، صف و خدمت در نرمافزار.
۴. اعتبارسنجی و تأیید مدل (Verification & Validation): توضیح تخصصی: چک کردن اینکه مدل درست کار میکند (Verification) و واقعی را نشان میدهد (Validation). به زبان ساده: مطمئن شو مدلت اشتباه نداره و مثل واقعیت کار میکنه. مثال: مقایسه نتایج مدل با دادههای واقعی بانک فعلی (اگر زمان انتظار مدل ۱۰ دقیقه شد، درست است).
۵. طراحی آزمایشها (Experiment Design): توضیح تخصصی: انتخاب سناریوهای مختلف برای تست (What-If Analysis). به زبان ساده: چه تغییراتی رو تست کنیم؟ مثال: سناریو ۱: وضعیت فعلی (۲ باجه). سناریو ۲: اضافه کردن ۱ باجه. سناریو ۳: سریعتر کردن خدمت با آموزش.
۶. اجرای شبیهسازی و جمعآوری خروجی (Simulation Runs & Output Analysis): توضیح تخصصی: اجرای چندین بار (Runs) برای آمار معتبر و تحلیل خروجیها (میانگین، واریانس). به زبان ساده: مدل رو کلی بار اجرا کن و نتایج رو ببین. مثال: اجرا برای ۱۰۰۰ مشتری – نتیجه: با ۳ باجه، زمان انتظار به ۴ دقیقه کاهش یافت.
۷. تحلیل نتایج و پیشنهاد راهحل (Analysis & Recommendations): توضیح تخصصی: مقایسه سناریوها و انتخاب بهترین با توجه به هزینه و عملکرد. به زبان ساده: بهترین گزینه رو انتخاب کن و گزارش بده. مثال: پیشنهاد: اضافه کردن یک باجه موقت در ساعات شلوغ، که زمان انتظار را ۶۰% کاهش میدهد با هزینه کم.
۸. پیادهسازی و مستندسازی (Implementation & Documentation): توضیح تخصصی: اعمال تغییرات در واقعیت و نوشتن گزارش کامل. به زبان ساده: تغییرات رو واقعی اجرا کن و همه چیز رو بنویس. مثال: بانک باجه جدید اضافه میکند و نتایج را نظارت میکند.
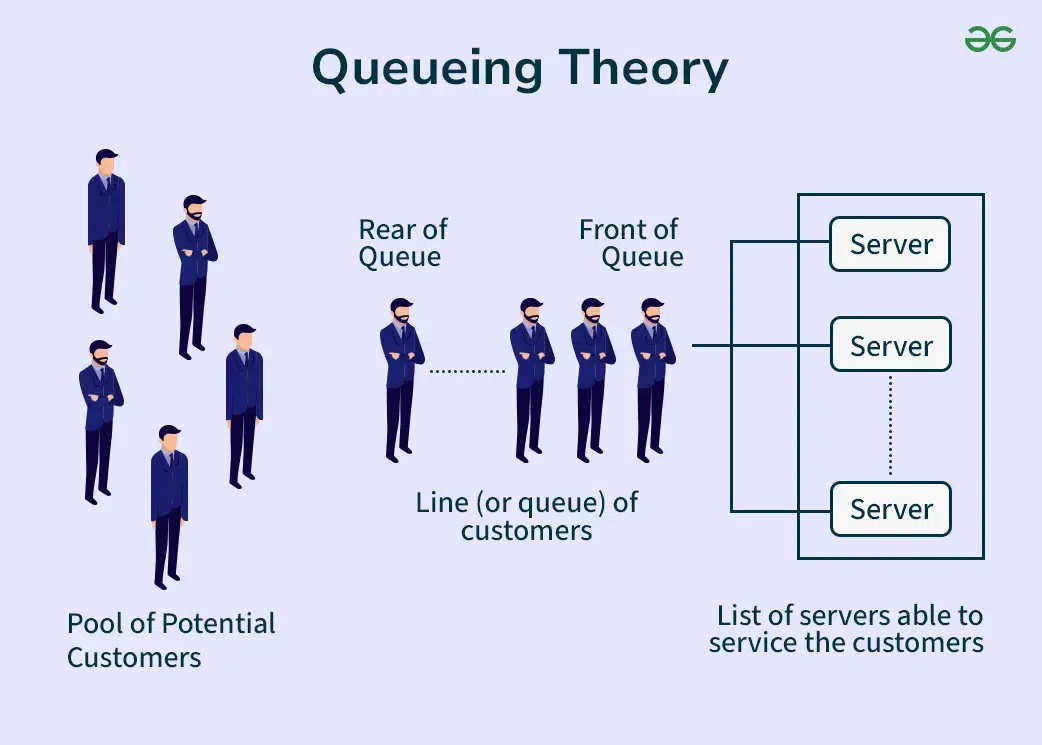
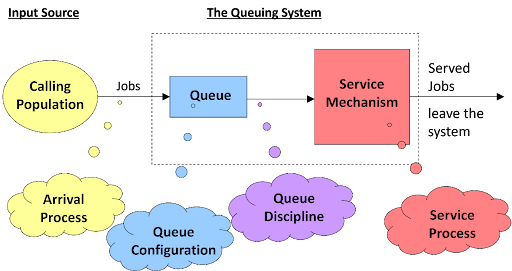
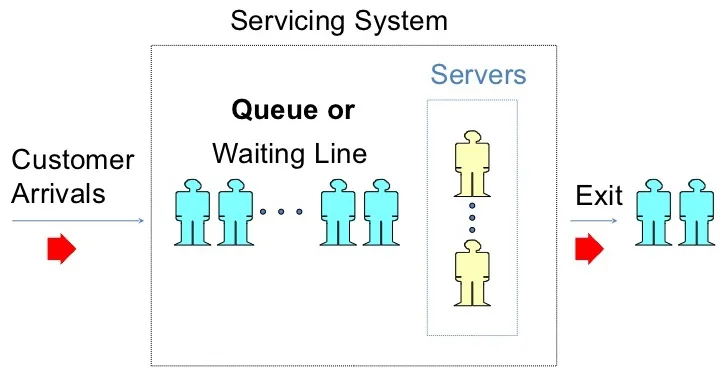
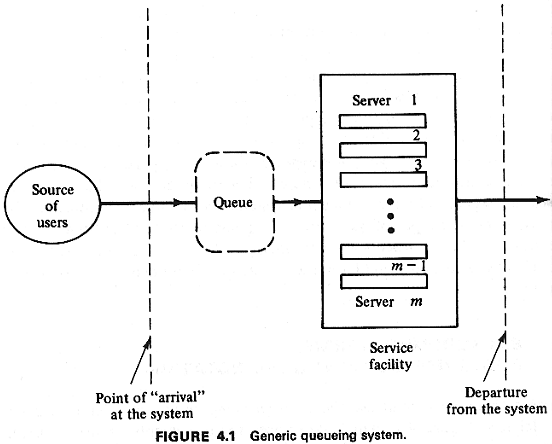
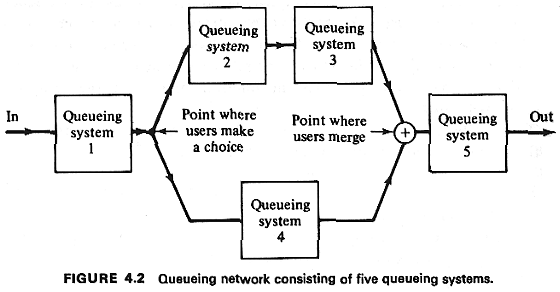
شبیهسازی سیستم صف (Queueing System)
سیستم صف یکی از رایجترین کاربردهای شبیهسازی گسسته پیشامد است (بر اساس نظریه صف Kendall’s Notation و کتاب جری بنکس و جان کارسن، ترجمه هاشم محلوجی، و منابع معتبر مانند GeeksforGeeks و ResearchGate).
(تصاویر بالا: دیاگرامهای استاندارد سیستم صف تکسرور (M/M/1) و کلی سیستم صف در شبیهسازی)
تعریف سیستم صف (توضیح تخصصی)
سیستم صف با چهار عنصر اصلی مشخص میشود:
- جمعیت متقاضی (Calling Population): منبع مشتریان یا موجودیتها.
- چگونگی ورود (Arrival Process): نرخ و توزیع ورود (مثل پواسون).
- ظرفیت سیستم (System Capacity): تعداد حداکثر در صف و خدمت.
- نظام صف (Queue Discipline): قانون صف (مثل FIFO: اول وارد، اول خارج).
در بسیاری مدلها (مثل M/M/1)، جمعیت متقاضی نامحدود فرض میشود: خروج یا خدمت یک مشتری تأثیری روی نرخ ورود دیگران ندارد (استقلال رویدادها).
به زبان ساده: سیستم صف جایی است که مشتریان وارد میشوند، اگر خدمتدهنده (سرور) مشغول باشد، منتظر میمانند و بعد خدمت میگیرند. جمعیت نامحدود یعنی همیشه مشتری جدید میآید، حتی اگر یکی برود!
(تصویر بالا: دیاگرام کلی نظریه صف)
مفاهیم کلیدی صف
توضیح تخصصی:
- حالت سیستم (System State): تعداد مشتریان حاضر در سیستم (در صف + در خدمت) و وضعیت خدمتدهنده (مشغول یا بیکار).
- رویدادها (Events): ورود (Arrival) و خروج (Departure) که وضعیت را تغییر میدهند.
به زبان ساده:
- حالت سیستم: چند نفر الان در بانک هست؟ خدمتدهنده مشغول است یا نه؟
- رویدادها: لحظه ورود مشتری جدید یا خروج مشتری پس از خدمت.
منظور از صف چیست؟
توضیح تخصصی: صف، بخشی از سیستم است که موجودیتها (مشتریان) برای دریافت خدمت منتظر میمانند، وقتی ظرفیت خدمتدهنده پر باشد.
به زبان ساده: صف یعنی جایی که مشتریها منتظر نوبت میمونن، مثل صف بانک یا سوپرمارکت. اگر شلوغ بشه، صف طولانی میشه و زمان انتظار زیاد – هدف شبیهسازی، کاهش این زمانه!

(تصویر بالا: مثال دستی شبیهسازی سیستم صف)
دیاگرام جریان ورود به سیستم (نرخ ورود – Arrival Process)
توضیح تخصصی: فرآیند ورود مشتریان به سیستم.
به زبان ساده (فلوچارت):
- شروع
- ورود مشتری
- چک کردن خدمتدهنده: اگر خالی باشد → مستقیم خدمت شروع میشود.
- اگر مشغول باشد → مشتری وارد صف میشود.
دیاگرام خدمتدهی (Service Process)
توضیح تخصصی: فرآیند خدمت و خروج از سیستم.
به زبان ساده (فلوچارت):
- مشتری از صف خارج میشود (اگر صف داشته باشیم)
- شروع خدمتدهی
- پایان خدمتدهی
- خروج مشتری از سیستم.

(تصاویر بالا: فلوچارت فرآیند خدمتدهی)
دیاگرامهای مهم و اساسی در سیستم صف (Queueing System Diagrams)
در شبیهسازی گسسته پیشامد، دیاگرامهای جریان (Flowcharts) ابزارهای کلیدی برای درک فرآیندهای ورود، خدمت و خروج هستند (بر اساس منابع استاندارد مانند کتاب جری بنکس و جان کارسن، ترجمه هاشم محلوجی، و سایتهای آموزشی ResearchGate، Fiveable و Towards Data Science).
(تصاویر بالا: دیاگرامهای کلی سیستم صف، اجزای اصلی و فلوچارت فرآیند ورود/خروج)
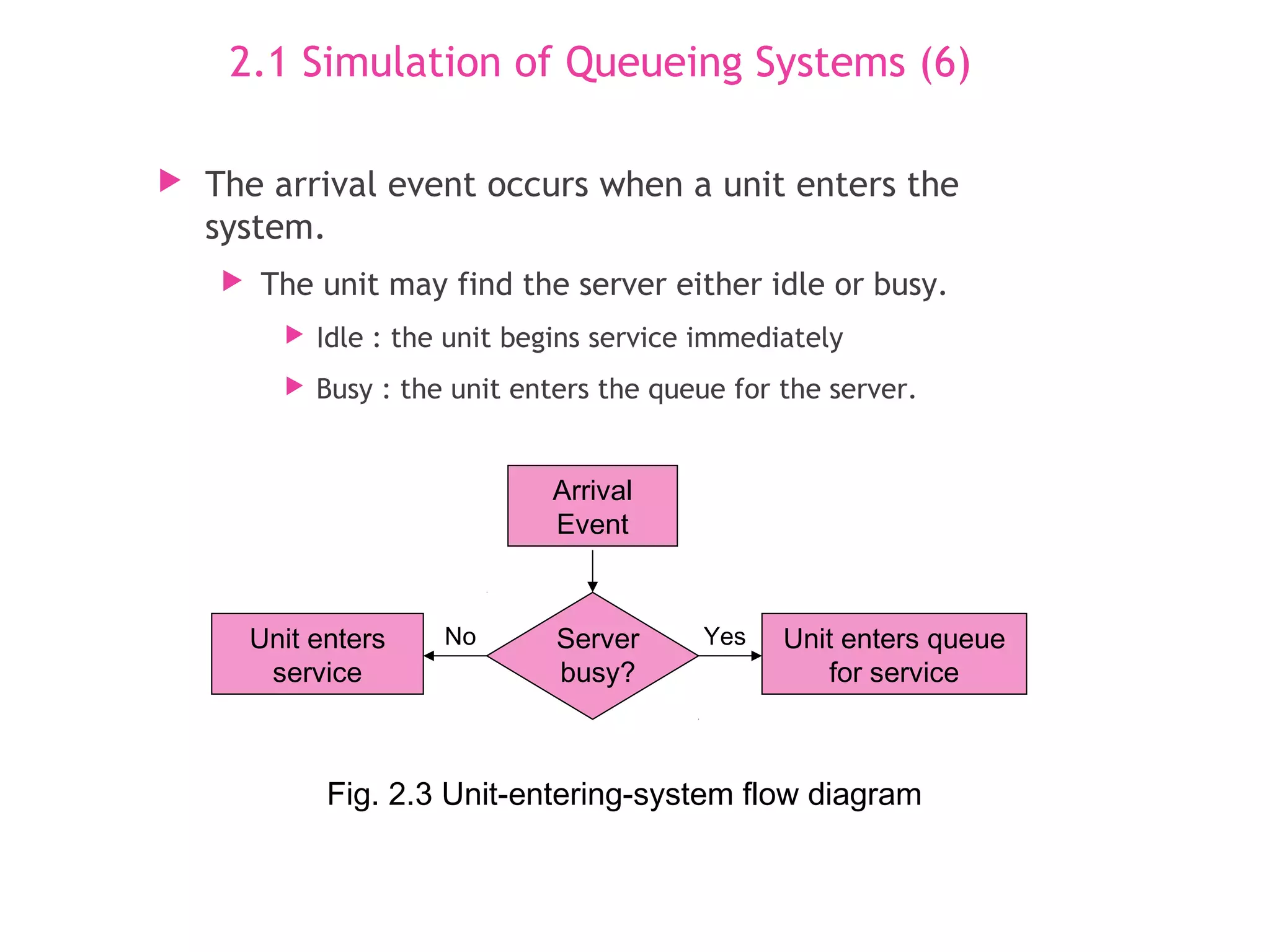
۱- دیاگرام جریان ورود به سیستم (Arrival Process Flowchart)
توضیح تخصصی: این دیاگرام فرآیند ورود متقاضی (مشتری) را نشان میدهد: ورود → چک وضعیت خدمتدهنده (سرور) → اگر خالی باشد، خدمت شروع میشود؛ اگر مشغول، وارد صف میشود.
به زبان ساده: وقتی مشتری میآید:
- اگر باجه خالی باشه، مستقیم میره خدمت.
- اگر مشغول باشه، میره تو صف منتظر بمونه.
(تصاویر بالا: فلوچارت دقیق فرآیند ورود در شبیهسازی گسسته)
عملیات متصور به هنگام ورود یک متقاضی
توضیح تخصصی:
- افزایش تعداد مشتریان در سیستم (N = N + 1).
- اگر خدمتدهنده بیکار باشد: شروع خدمت و زمانبندی رویداد خروج.
- اگر مشغول باشد: اضافه شدن به صف و افزایش طول صف.
به زبان ساده: وقتی یکی وارد میشه: تعداد آدمها یکی بیشتر میشه. اگر کسی مشغول نباشه، فوری خدمت شروع میشه؛ وگرنه، میره آخر صف!
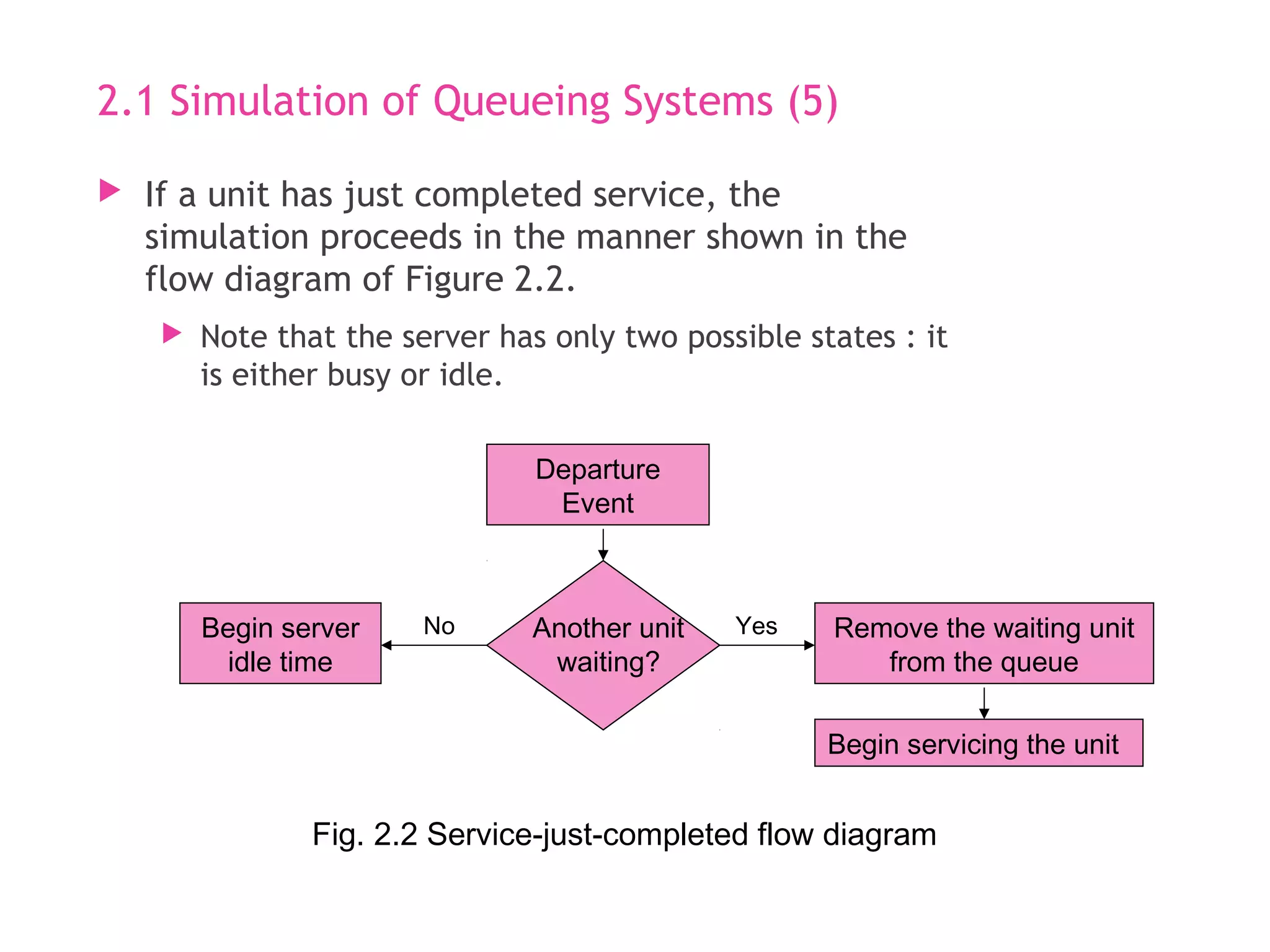
۲- دیاگرام جریان خدمتدهی و تکمیل خدمت (Service Completion & Departure Process)
توضیح تخصصی: این دیاگرام فرآیند پس از تکمیل خدمت را نشان میدهد: پایان خدمت → خروج مشتری → چک صف → اگر صف داشته باشیم، مشتری بعدی وارد خدمت میشود؛ اگر نه، خدمتدهنده بیکار میشود.
به زبان ساده: وقتی خدمت یکی تموم میشه:
- مشتری میره بیرون.
- اگر کسی تو صف باشه، بعدی میآد خدمت.
- اگر صف خالی باشه، باجه بیکار میمونه تا مشتری جدید بیاد.
(تصاویر بالا: فلوچارت تکمیل خدمت و خروج در سیستم صف)
وضعیت خدمتدهنده پس از تکمیل خدمتدهی
توضیح تخصصی:
- کاهش تعداد مشتریان در سیستم (N = N – 1).
- اگر طول صف > ۰ باشد: خدمتدهنده همچنان مشغول (مشتری بعدی وارد خدمت).
- اگر طول صف = ۰ باشد: خدمتدهنده بیکار (Idle) میشود تا رویداد ورود بعدی.
به زبان ساده: بعد از رفتن مشتری: اگر هنوز کسی تو صف باشه، باجه مشغول میمونه؛ اگر نه، خالی و منتظر مشتری جدید میشه!
این دیاگرامها پایه دستی و کامپیوتری شبیهسازی صف هستند – با دونستنشون، میتونی مدل بانک یا بیمارستان رو راحت بسازی!
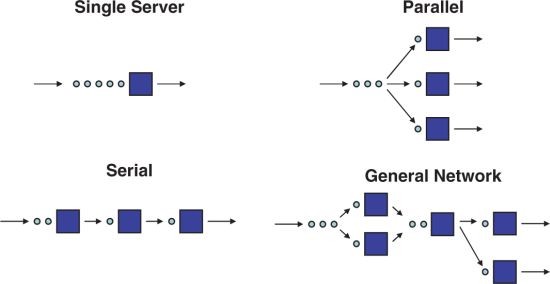
صفهای تکمجرایی (Single Server / Single Channel Queue)
تعریف صف تکمجرایی (توضیح تخصصی)
صف تکمجرایی یا تکسرور (Single Server Queue)، مدلی در نظریه صف است که فقط یک خدمتدهنده (سرور یا مجرا) وجود دارد. مشتریان یکی یکی وارد میشوند، اگر سرور مشغول باشد، در صف منتظر میمانند و به ترتیب (معمولاً FIFO) خدمت میگیرند. این مدل معروف به M/M/1 است (ورود پواسون، خدمت نمایی، یک سرور) و پایه بسیاری از شبیهسازیهای گسسته پیشامد است (بر اساس کتاب جری بنکس و جان کارسن، ترجمه هاشم محلوجی، و منابع MathWorks و Springer).
به زبان ساده: یعنی فقط یک باجه یا یک نفر خدمت میده! مشتریها پشت سر هم میان، اگر باجه مشغول باشه، صف میکشن و یکی یکی نوبتشون میشه.
(تصاویر بالا: دیاگرامهای استاندارد صف تکمجرایی و مدل M/M/1)
مثالهای ساده از صف تکمجرایی
به زبان ساده:
- بانک با فقط یک صندوقدار: همه مشتریان پشت یک صف میایستن و یکی یکی کارشون انجام میشه.
- عابر بانک (ATM): فقط یک دستگاه، مردم صف میکشن تا نوبتشون بشه.
- مطب دکتر با یک پزشک: بیماران منتظر میمونن تا دکتر یکی یکی ویزیت کنه.
- باجه بلیت سینما یا ایستگاه تاکسی با یک راننده.
(تصاویر بالا: مثالهای واقعی صف تکمجرایی مثل بانک یا عابر بانک)
در شبیهسازی صف تکمجرایی (توضیح تخصصی)
در مدل تکمجرایی، زمان بین ورود دو مشتری متوالی (Interarrival Time) و زمان خدمتدهی (Service Time) به عنوان متغیرهای تصادفی تولید یا تعیین میشوند (معمولاً با توزیعهای یکنواخت، نمایی یا پواسون). این زمانها با تولید اعداد تصادفی شبیهسازی میشوند تا رفتار سیستم پیشبینی شود.
به زبان ساده: برای شبیهسازی، زمان رسیدن مشتریها و زمان خدمت رو مثل تاس ریختن، تصادفی انتخاب میکنیم تا ببینیم صف چقدر طولانی میشه یا زمان انتظار چقدره.
مثال عملی (بر اساس جزوه): فرض کنید در یک صف تکمجرایی:
- زمان بین ورود دو مشتری متوالی: بین ۱ تا ۸ دقیقه، با احتمال برابر (یکنواخت).
- زمان خدمتدهی: بین ۱ تا ۶ دقیقه، با احتمالات جدول زیر (جدول رو بعداً کامل کن، اما مثلاً احتمالها متفاوت باشن).
در شبیهسازی دستی یا کامپیوتری، برای هر مشتری جدید:
- زمان ورود بعدی رو تصادفی انتخاب کن (مثلاً ۴ دقیقه بعد).
- زمان خدمت رو تصادفی انتخاب کن (مثلاً ۳ دقیقه).
- سپس وضعیت صف، زمان انتظار و تعداد مشتریان رو محاسبه کن.
این مدل کمک میکنه ببینی با یک باجه، صف چقدر شلوغ میشه و آیا نیاز به باجه دوم هست یا نه!

(تصاویر بالا: شبیهسازی و مثال عددی صف تکمجرایی)
مسئله پسرک روزنامهفروش (Newsvendor Problem یا Newsboy Problem)
این مسئله یکی از مثالهای کلاسیک در شبیهسازی سیستمهای موجودی تکدورهای است (بر اساس کتاب جری بنکس و جان کارسن، ترجمه هاشم محلوجی، فصل سیستمهای موجودی، و منابع استاندارد تحقیق عملیات مانند Wikipedia و سایتهای آموزشی Cornell و MIT).
توضیح تخصصی
پسرک روزنامهفروش صبحها تعدادی روزنامه با هزینه خرید مشخص (c = ۱۳ تومان) میخرد و با قیمت فروش (r = ۲۰ تومان) میفروشد. تقاضای روزانه تصادفی است و روزنامههای باقیمانده در پایان روز به عنوان باطله فروخته میشوند (در این مثال، salvage value = ۰ تومان، یعنی زیان کامل). هدف: تعیین تعداد سفارش بهینه (Q) برای بیشینه کردن سود مورد انتظار، با شبیهسازی تقاضا و محاسبه سود/زیان.
فرمول سود روزانه: سود = درآمد فروش + درآمد باطله – هزینه خرید
- تعداد فروش = min(Q, تقاضا روزانه)
- تعداد باطله = max(Q – تقاضا, ۰)
- اگر تقاضا > Q، فرصت فروش از دست رفته (زیان فرصت).
به زبان ساده: پسرک نمیدونه امروز چند نفر روزنامه میخوان! اگر زیاد بخره، باطله میمونه و ضرر میکنه. اگر کم بخره، مشتریها میرن و سود از دست میده. با شبیهسازی تقاضا، بهترین تعداد رو پیدا میکنیم تا میانگین سود حداکثر بشه.
شبیهسازی دو سناریو (با سفارش روزانه ۶۰ روزنامه)
فرض: هزینه خرید ۱۳ تومان، قیمت فروش ۲۰ تومان، باطله ۰ تومان (زیان کامل). تقاضای میانگین حدود ۵۰.
۱- سناریو تقاضای کم (۵۰ روزنامه – ۱۰ باطله): توضیح تخصصی: فروش = ۵۰، باطله = ۱۰، درآمد فروش = ۵۰ × ۲۰ = ۱۰۰۰ تومان، هزینه خرید = ۶۰ × ۱۳ = ۷۸۰ تومان، درآمد باطله = ۰. سود = ۱۰۰۰ – ۷۸۰ = ۲۲۰ تومان (زیان باطله = ۱۰ × ۱۳ = ۱۳۰ تومان که در محاسبه کسر شده؛ کمبود تقاضا زیان اضافی ندارد).
به زبان ساده: همه ۵۰ روزنامه فروخته شد، ۱۰ تا باطله موند و ضرر کامل خورد. سود خالص ۲۲۰ تومان – بهتر از کمبود نبود!
۲- سناریو تقاضای صفر (۰ روزنامه – ۶۰ باطله): توضیح تخصصی: فروش = ۰، باطله = ۶۰، درآمد فروش = ۰، هزینه خرید = ۶۰ × ۱۳ = ۷۸۰ تومان، درآمد باطله = ۰. سود = ۰ – ۷۸۰ = -۷۸۰ تومان (زیان کامل کل سفارش).
به زبان ساده: هیچکس روزنامه نخرید! همه ۶۰ تا باطله شد و ۷۸۰ تومان ضرر کرد – بدترین حالت ممکن!
در شبیهسازی واقعی، تقاضا را تصادفی تولید میکنیم (مثل توزیع نرمال یا پواسون با میانگین ۵۰) و برای هزاران روز اجرا میکنیم تا سود میانگین و تعداد بهینه سفارش (معمولاً نزدیک میانگین تقاضا + کمی بیشتر) را پیدا کنیم. این مسئله نشان میدهد چطور شبیهسازی کمک میکنه ریسک موجودی فاسدشدنی رو مدیریت کنیم!
صف چندمجرایی (Multi-Server Queue) و مدلهای آماری (Stochastic Models) در شبیهسازی
صف چندمجرایی (۲ خدمتدهنده) (توضیح تخصصی)
در نظریه صف، مدل چندمجرایی یا چندسرور (Multi-Server Queue) مانند M/M/c (c تعداد سرورها) است، جایی که مشتریان در یک صف مشترک منتظر میمانند و به اولین سرور خالی میشوند. برای c=۲، دو خدمتدهنده مستقل وجود دارد که زمان خدمت معمولاً نمایی است. این مدل کارایی بیشتری نسبت به تکمجرایی دارد (زمان انتظار کمتر) و در شبیهسازی گسسته پیشامد برای سیستمهای واقعی استفاده میشود (بر اساس کتاب جری بنکس و جان کارسن، ترجمه هاشم محلوجی، و منابع مانند Operations Research).
به زبان ساده: تصور کن بانکی با دو باجه! مشتریان در یک صف مشترک میایستن و به هر باجهای که زودتر خالی شد، میرن. صف سریعتر حرکت میکنه و زمان انتظار کمتر میشه – خیلی بهتر از یک باجه تنها!
![PDF] Bank Service Performance Improvements using Multi-Sever Queue ...](https://figures.semanticscholar.org/1e057ebf77603db3ab74cabcdc13a68647e6a6e9/3-Figure1-1.png)
(تصاویر بالا: دیاگرامهای صف دوباجه بانک و مدل چندسرور)
مدلهای آماری (Stochastic Models) در شبیهسازی (اشاره به پیشامدهای غیرمنتظره)
توضیح تخصصی: در مدلسازی پدیدههای واقعی، رفتار موجودیتها اغلب تصادفی (Stochastic) است و نمیتوان آن را قطعی (Deterministic) پیشبینی کرد. جهان واقعی پر از عدم قطعیت است، پس از مدلهای احتمالی استفاده میکنیم که رویدادها را با توزیعهای آماری (مثل نمایی، پواسون یا یکنواخت) شبیهسازی میکنند. این مدلها پیشامدهای غیرمنتظره (Random Events) را با تولید اعداد تصادفی مدیریت میکنند (بر اساس منابع معتبر مانند Investopedia و Corporate Finance Institute در مورد Stochastic Modeling).
به زبان ساده: دنیای واقعی مثل یک بازی پر از شانس است – نمیتونی دقیق بگی چی پیش میآد! مثلاً در هوش مصنوعی خودروهای خودران تسلا (FSD)، ماشین باید به اتفاقات ناگهانی مثل دویدن بچه جلوی ماشین یا تغییر ناگهانی آب و هوا واکنش بده. شبیهسازی این رویدادهای تصادفی کمک میکنه ماشین بهتر یاد بگیره.

دلایل به هم خوردن پیشبینیها (عدم قطعیت)
توضیح تخصصی: زمان خدمت یا رویدادها تابعی از عوامل تصادفی است، مثل پیچیدگی خرابی، دسترسی به ابزار، دخالت عوامل خارجی یا دانش مشتری.
به زبان ساده: مثلاً در تعمیرگاه ماشین:
- زمان تعمیر یک ماشین تصادفی بستگی به این داره که خرابی چقدر پیچیده باشه.
- آیا تعمیرکار ابزار و قطعه لازم رو داره؟
- وسط کار، تعمیرکار دیگهای میآد کمک یا مزاحم میشه؟
- صاحب ماشین چقدر از نگهداری ماشین سر در میآره (مثلاً منظم سرویس کرده یا نه)؟
مدلساز اینها رو “اتفاقی و غیرقابل پیشبینی دقیق” فرض میکنه و با اعداد تصادفی شبیهسازی میکنه تا ببینه سیستم در بدترین/بهترین حالت چطور کار میکنه.

(تصاویر بالا: دیاگرام شبیهسازی صف تعمیرگاه خودرو)
متغیرهای تصادفی گسسته (Discrete Random Variables)
توضیح تخصصی
متغیر تصادفی گسسته (Discrete Random Variable)، متغیری است که مقادیر ممکن آن متناهی (محدود) یا نامتناهی اما قابل شمارش (مثل اعداد طبیعی) باشد. فضای نمونه (Sample Space) آن شامل نقاط جدا از هم است (بر اساس منابع استاندارد مانند کتاب «احتمال و آمار مهندسی» نوشته والپول و مایرز، کتاب «شبیهسازی» بنکس و کارسن ترجمه محلوجی، و سایتهای آموزشی Khan Academy و StatLect).
فضای دامنه (Support): مجموعه مقادیر ممکن X که با RX نشان داده میشود.
تابع جرم احتمال (Probability Mass Function – PMF): برای هر xi در RX، مقدار:
p(xi)=P(X=xi)
را تابع جرم احتمال میگویند. این تابع باید دو شرط را داشته باشد:

به زبان ساده: متغیر تصادفی گسسته مثل نتیجه یک بازی شانسی است که فقط چند جواب مشخص و جدا از هم داره – مثلاً تعداد بچههای یک خانواده، تعداد ماشینهای عبوری در یک ساعت، یا عدد روی تاس. نمیتونه مقداری بین دو عدد بگیره (مثل ۳.۵ روی تاس نمیآد!).
مثال ساده: تاس (حتی تاس شکسته!)
توضیح تخصصی: فرض کنید X تعداد چشمان روی تاس باشد. در تاس سالم:
RX={1,2,3,4,5,6} و p(xi)=61
برای هر کدام.
اگر تاس شکسته باشد (مثلاً عدد ۶ بیشتر میآید): مثال توزیع ممکن:
- p(1)=0.1, p(2)=0.1, p(3)=0.1, p(4)=0.1, p(5)=0.1, p(6)=0.5
به زبان ساده: وقتی تاس میاندازی، X یعنی “عدد رو به بالا”. اگر تاس سالم باشه، شانس همه اعداد برابر است. اما اگر شکسته باشه و مثلاً ۶ بیشتر بیاد، احتمال ۶ رو بیشتر میذاریم (مثل ۵۰%) و بقیه کمتر – ولی جمع شانسها همیشه باید ۱۰۰% بشه! هیچ احتمالی منفی یا بیشتر از کل نمیتونه باشه.
(تصاویر بالا: دیاگرام تابع جرم احتمال (PMF) برای تاس سالم و توزیع گسسته مثال)
در شبیهسازی، متغیرهای گسسته مثل تعداد مشتریان ورودی یا تعداد خرابیها رو با این توزیعها مدل میکنیم تا رفتار تصادفی سیستم رو دقیق نشون بدیم!
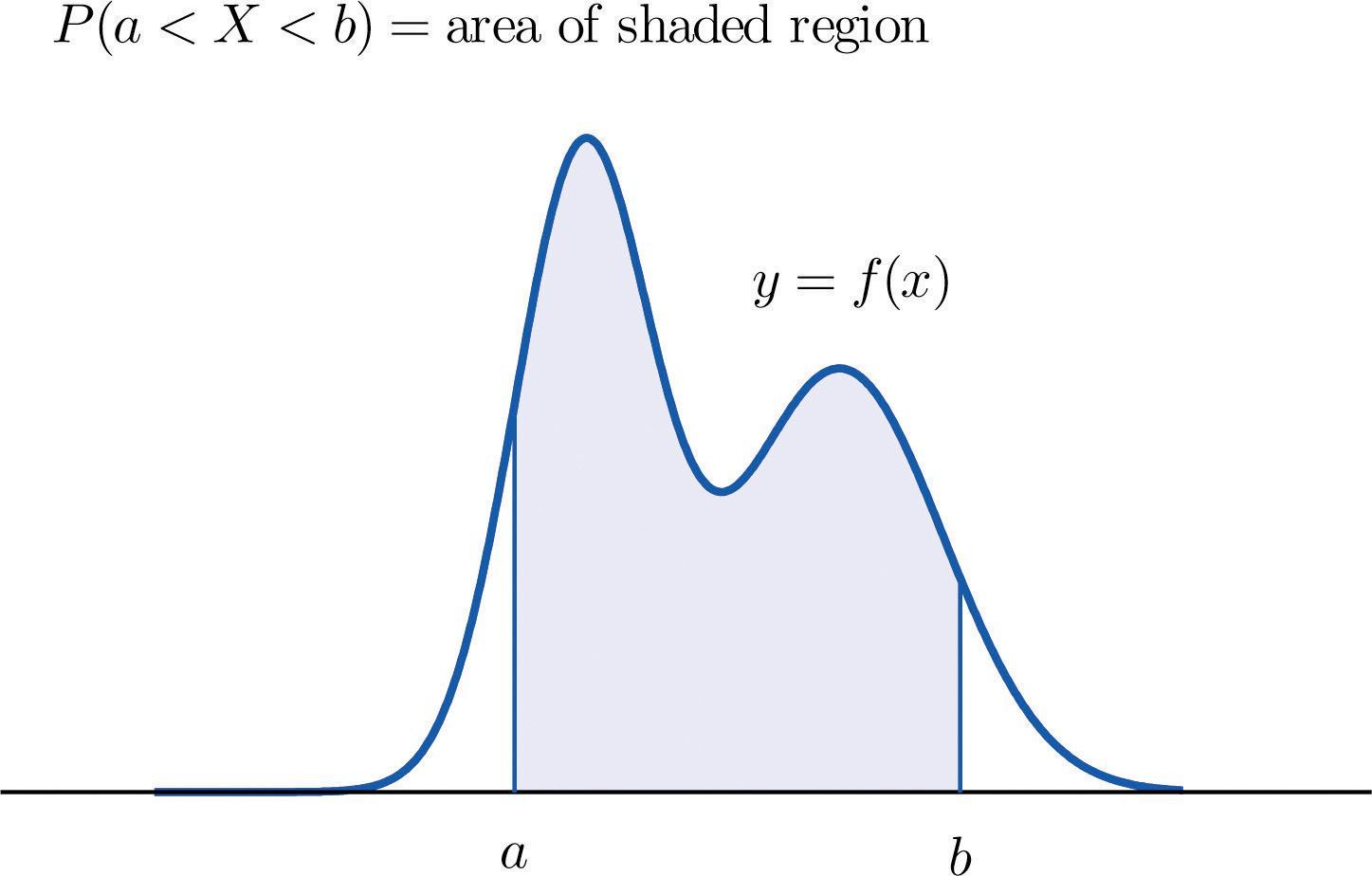
متغیرهای تصادفی پیوسته (Continuous Random Variables)
توضیح تخصصی
متغیر تصادفی پیوسته (Continuous Random Variable)، متغیری است که فضای دامنه آن (Support) یک فاصله پیوسته یا مجموعهای از فواصل روی محور اعداد واقعی باشد (مثل [a, b] یا تمام اعداد واقعی). احتمال وقوع یک مقدار دقیق (مثل P(X = c)) همیشه صفر است، چون نقاط بینهایت هستند؛ در عوض، احتمال را برای بازهها محاسبه میکنیم: P(a ≤ X ≤ b).
تابع چگالی احتمال (Probability Density Function – PDF): تابع f(x) را PDF مینامند که باید دو شرط داشته باشد:
- f(x) ≥ ۰ برای همه x.
- انتگرال از -∞ تا +∞ f(x) dx = ۱ (مساحت زیر منحنی برابر ۱).
احتمال در بازه [a, b] برابر انتگرال f(x) از a تا b است (بر اساس منابع استاندارد مانند کتاب «احتمال و آمار مهندسی» والپول، Khan Academy و StatLect).

(تصاویر بالا: منحنیهای تابع چگالی احتمال PDF برای توزیعهای پیوسته مثل نرمال)
مثال به زبان ساده
توضیح تخصصی: مثل قد افراد (X میتواند هر عددی بین مثلاً ۱۴۰ تا ۲۲۰ سانتیمتر باشد، حتی ۱۷۲.۳۴۵ سانتیمتر). احتمال دقیق X=۱۷۰ صفر است، اما احتمال بین ۱۶۵ تا ۱۷۵ سانتیمتر (مثل P(165 ≤ X ≤ 175)) یک عدد مثبت است که از مساحت زیر PDF محاسبه میشود.
به زبان ساده: متغیر پیوسته مثل اندازهگیری چیزی که میتونه هر عددی در یک بازه بگیره – نه فقط اعداد درست! مثلاً:
- زمان انتظار در صف بانک (میتونه ۳.۲ دقیقه، ۴.۷ دقیقه یا هر چیزی باشه).
- وزن یک نفر (۱۷۲.۵ کیلو، ۱۷۲.۵۱ کیلو و…).
- دمای هوا (۲۵.۳ درجه).
احتمال دقیق یک عدد (مثل دقیق ۱۷۰ سانتیمتر قد) صفره، چون بینهایت امکان هست؛ اما احتمال “قد بین ۱۶۰ تا ۱۸۰” رو میتونیم حساب کنیم، مثل مساحت زیر یک منحنی زنگولهای!
(تصاویر بالا: مقایسه گرافیکی متغیر تصادفی گسسته (میلهای) در مقابل پیوسته (منحنی صاف))

(تصاویر بالا: مثالهای واقعی متغیرهای پیوسته مثل قد، وزن و زمان)
تابع توزیع تجمعی (Cumulative Distribution Function – CDF)
توضیح تخصصی
تابع توزیع تجمعی (CDF)، با نماد F(x) (نه f(x) – توجه: f(x) معمولاً برای PDF است)، احتمال اینکه متغیر تصادفی X مقداری کمتر یا مساوی x بگیرد را اندازهگیری میکند: F(x) = P(X ≤ x)
این تابع برای هر دو نوع متغیر تصادفی (گسسته و پیوسته) تعریف میشود و ویژگیهای زیر را دارد (بر اساس منابع استاندارد مانند کتاب «احتمال و آمار مهندسی» والپول، ProbabilityCourse.com و StatisticsByJim):
- غیرنزولی (Non-decreasing): اگر a < b، آنگاه F(a) ≤ F(b).
- حد وقتی x → +∞: F(x) → ۱ (تمام احتمالات را پوشش میدهد).
- حد وقتی x → -∞: F(x) → ۰.
- برای متغیرهای گسسته، CDF تابعی پلهای (Step Function) است: ثابت میماند و در نقاط ممکن X جهش میکند به اندازه p(x_i).
به زبان ساده: CDF بهت میگه “شانس اینکه نتیجه کمتر یا مساوی یک عدد خاص باشه چقدره؟” مثلاً اگر قد افراد رو در نظر بگیریم، F(۱۷۰) یعنی درصد افرادی که قدشون ۱۷۰ سانتیمتر یا کمتره.
(تصاویر بالا: ویژگیهای CDF – غیرنزولی بودن، حد ۰ و ۱)
CDF برای متغیر تصادفی گسسته (مثال تاس ناسالم)
توضیح تخصصی: اگر X متغیر گسسته با مقادیر مرتب x₁ < x₂ < … باشد، CDF پلهای است: تا قبل از x_i ثابت میماند و در x_i به اندازه P(X = x_i) جهش میکند. مثال تاس ناسالم (فرض کنیم احتمالات متفاوت، مثلاً جمع ۲۱ واحد احتمال برای سادهسازی): اگر P(X=۳) = ۳/۲۱ باشد، CDF در نقطه ۳ به اندازه ۳/۲۱ بالا میپره.
به زبان ساده: CDF برای تاس مثل یک پله است – تا قبل از یک عدد ثابت میمونه، بعد ناگهان میپره بالا به اندازه شانس اون عدد. مثلاً اگر شانس اومدن ۳ برابر ۳/۲۱ باشه، گراف CDF دقیقاً در ۳ اینقدر جهش میکنه!
دلیل اینکه حالت های پرتاب تاس ما از یک تا ۶ شده ۲۱ چیست؟
مجموع اعداد روی یک تاس (۱+۲+۳+۴+۵+۶=۲۱) به خاطر بالانس فیزیکی تاس طراحی شده؛ وجوه مقابل هم همیشه جمعشون ۷ میشه (۱ مقابل ۶، ۲ مقابل ۵، ۳ مقابل ۴)، پس ۳ جفت * ۷ = ۲۱، تا تاس عادلانه بچرخه و تقلب نشه.
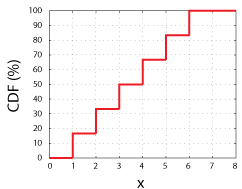
(تصاویر بالا: گراف CDF پلهای برای تاس و مثالهای گسسته)
مقایسه CDF و PDF
به زبان ساده: PDF (چگالی) ارتفاع میله یا منحنی رو نشون میده، اما CDF جمع تجمعیشونه – همیشه از ۰ شروع میشه و به ۱ میرسه!

(تصاویر بالا: مقایسه PDF و CDF برای گسسته و پیوسته)
مثال لامپ صنعتی (Industrial Lamp Example) و محاسبه CDF
این مثال از کتاب استاندارد Discrete-Event System Simulation نوشته جری بنکس و جان کارسن (ترجمه هاشم محلوجی، انتشارات دانشگاه صنعتی شریف) گرفته شده و یکی از مثالهای کلاسیک برای توضیح توزیعهای گسسته و CDF در شبیهسازی است. در این مثال، عمر یک لامپ صنعتی (industrial lamp) به عنوان متغیر تصادفی گسسته مدل میشود (بر اساس دادههای واقعی یا فرضی در کتاب).
توضیح تخصصی
فرض کنید عمر لامپ (X به هزار ساعت) مقادیر گسسته ۱، ۲، ۳، ۴، ۵، ۶ را میگیرد (مثل یک توزیع مثلثی یا خاص برای نشان دادن عدم یکنواختی). توزیع احتمال (PMF) به صورت زیر است (مثال معروف کتاب برای توضیح CDF گسسته):
| x_i (عمر لامپ) | ۱ | ۲ | ۳ | ۴ | ۵ | ۶ |
|---|---|---|---|---|---|---|
| p(x_i) | ۱/۲۱ | ۲/۲۱ | ۳/۲۱ | ۴/۲۱ | ۵/۲۱ | ۶/۲۱ |
(جمع احتمالات = (۱+۲+۳+۴+۵+۶)/۲۱ = ۲۱/۲۱ = ۱ ✓)
تابع توزیع تجمعی CDF – F(x) = P(X ≤ x): سی دی اف برای متغیر گسسته پلهای است و جمع احتمالات تا x را نشان میدهد:
| x | F(x) = P(X ≤ x) |
|---|---|
| x < ۱ | ۰ |
| ۱ ≤ x < ۲ | ۱/۲۱ |
| ۲ ≤ x < ۳ | ۱/۲۱ + ۲/۲۱ = ۳/۲۱ |
| ۳ ≤ x < ۴ | ۳/۲۱ + ۳/۲۱ = ۶/۲۱ |
| ۴ ≤ x < ۵ | ۶/۲۱ + ۴/۲۱ = ۱۰/۲۱ |
| ۵ ≤ x < ۶ | ۱۰/۲۱ + ۵/۲۱ = ۱۵/۲۱ |
| x ≥ ۶ | ۱۵/۲۱ + ۶/۲۱ = ۲۱/۲۱ = ۱ |
به زبان ساده: تصور کن عمر یک لامپ صنعتی رو اندازه گرفتی و دیدی شانس اینکه دقیق ۱ هزار ساعت دوام بیاره کمه (۱/۲۱)، اما شانس ۶ هزار ساعت دوام آوردن زیاده (۶/۲۱). CDF بهت میگه “شانس اینکه لامپ حداقل تا اینقدر ساعت کار کنه چقدره؟” مثلاً F(۳) = ۶/۲۱ یعنی حدود ۲۸% لامپها تا ۳ هزار ساعت یا کمتر کار میکنن. گراف CDF مثل پله میره بالا – در هر عدد ممکن، یه جهش به اندازه احتمال اون عدد داره!
یادآوری مشتق و انتگرال
y=4x² dy/dx=8x ∫= (4/3)x³ + c
y=sinx dy/dx=cos x ∫= -cosx + c
y=4x²+sinx dy/dx=8x+cosx ∫= (4/3)x³ – cosx + c
y=e^{-x} dy/dx=-e^{-x} ∫= -e^{-x} + c
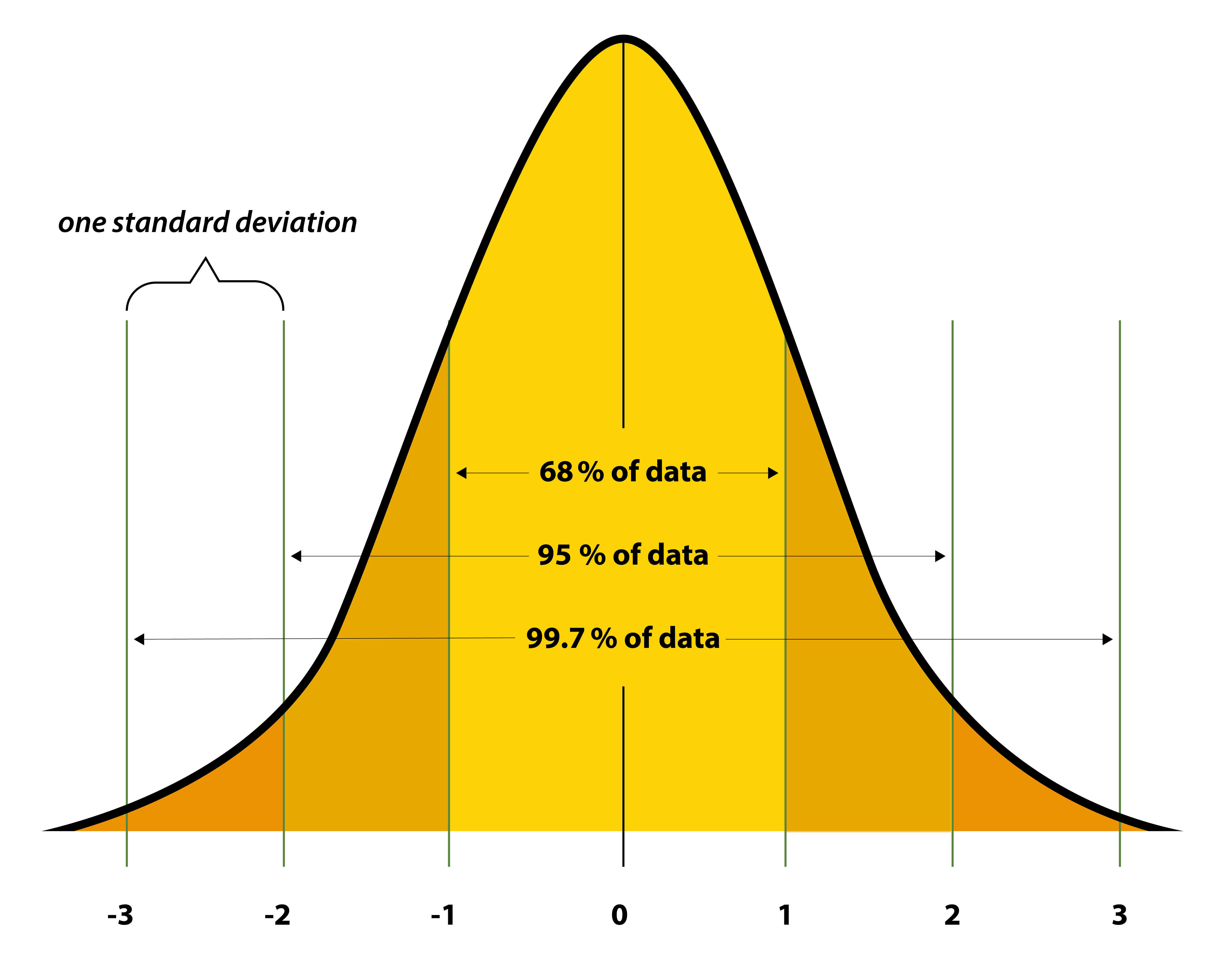
امید ریاضی (Expected Value)، واریانس (Variance) و انحراف معیار (Standard Deviation)
این مفاهیم پایهای آمار و احتمال هستند و در شبیهسازی برای تحلیل خروجیها (مثل میانگین زمان انتظار یا پراکندگی نتایج) خیلی مهماند (بر اساس منابع معتبر مانند کتاب «احتمال و آمار مهندسی» والپول و مایرز، Khan Academy و سایتهای آموزشی StatLect و MathIsFun).
امید ریاضی (Expected Value – E(X))
توضیح تخصصی: امید ریاضی، میانگین وزنی مقادیر ممکن متغیر تصادفی X است و مقدار “قابل انتظار” بلندمدت را نشان میدهد.
این معیار مرکزی (Center of Gravity) توزیع است.
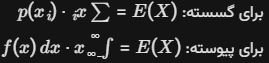
به زبان ساده: امید ریاضی یعنی “اگر این آزمایش رو میلیون بار تکرار کنی، میانگین نتیجه چقدر میشه؟” مثل میانگین نمره کلاس – بهترین پیشبینی برای یک بار بعدی!
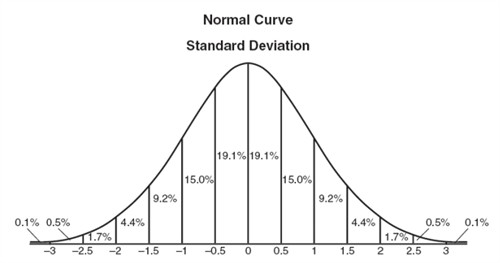
(تصاویر بالا: منحنی توزیع نرمال با میانگین و انحراف معیار – امید ریاضی نقطه مرکزی است)
واریانس (Variance – Var(X)) و انحراف معیار
توضیح تخصصی:
واریانس پراکندگی دادهها امید ریاضی را اندازه میگیرد:
Var(X)=E[(X−E(X))2]=E(X2)−[E(X)]2
انحراف معیار
σ=Var(X)
جذر واریانس است و واحد همان دادهها را دارد (آسانتر برای تفسیر).
به زبان ساده: واریانس نشون میده دادهها چقدر از میانگین پخش شدن (هرچی بزرگتر، پراکندهتر). انحراف معیار مثل “به طور متوسط، چقدر فاصله از میانگین داریم” – مثل نمره از ۱۰۰، قابل فهمتره!
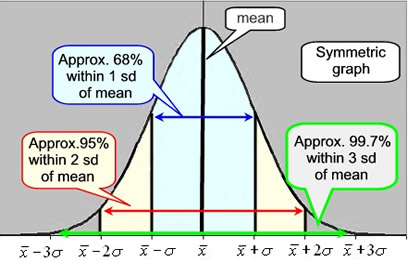
(تصاویر بالا: مثال تصویری پراکندگی با قد افراد – گروه نزدیک vs گروه پراکنده)
مثال واقعی و ساده (قد کلاس)
توضیح تخصصی: قدهای ۱۶۰، ۱۶۲، ۱۶۵، ۱۷۰، ۱۷۳: میانگین ≈ ۱۶۶ cm، واریانس کم، انحراف معیار ≈ ۵ cm (پراکندگی کم). قدهای ۱۵۰، ۱۵۵، ۱۶۵، ۱۷۵، ۱۸۰: انحراف معیار ≈ ۱۲ cm (پراکندگی بیشتر).
به زبان ساده: در کلاس اول همه قدشون نزدیک همدیگهست (انحراف کم)، در کلاس دوم کوتاه و بلند قاطی (انحراف زیاد) – انحراف معیار میگه “به طور متوسط، قد چقدر از ۱۶۶ فاصله داره”.
مثال تاس ناسالم (احتمال ۶ برابر ۰.۵، بقیه ۰.۱)
توضیح تخصصی (محاسبه دقیق): E(X)=1(0.1)+2(0.1)+3(0.1)+4(0.1)+5(0.1)+6(0.5)=۴.۵ Var(X)=E(X2)−[E(X)]2=۲۳.۵−(۴.۵)۲=۳.۲۵
انحراف معیار ≈ ۱.۸۰
در شبیهسازی ۱۰۰۰ پرتاب: میانگین تجربی ≈ ۴.۵۴، واریانس ≈ ۳.۲۰ (نزدیک به تئوری).
به زبان ساده: تاس ناسالم بیشتر ۶ میآره، پس میانگین حدود ۴.۵ میشه (بالاتر از تاس سالم که ۳.۵ بود). پراکندگی هم زیاده چون گاهی عدد کم میآد، گاهی ۶!
![OC] Visualizing the impact of dice choice on outcome : r/DnD](https://i.redd.it/1ggfi26or8271.png)
(تصاویر بالا: گرافهای امید ریاضی و واریانس برای پرتاب تاس)
مدلهای آماری سودمند در شبیهسازی (Stochastic Models in Simulation)
در شبیهسازی گسسته پیشامد، مدلهای آماری (تصادفی) برای شبیهسازی رویدادهای غیرقابل پیشبینی دقیق استفاده میشوند. زمان بین ورودها (Interarrival Time) و زمان خدمتدهی (Service Time) اغلب تصادفی هستند، و شبیهساز با تولید اعداد تصادفی این پیشامدها را مدل میکند (بر اساس کتاب جری بنکس و جان کارسن، ترجمه هاشم محلوجی، و منابع معتبر مانند INFORMS و ResearchGate).
(تصاویر بالا: دیاگرامهای سیستم صف با زمانهای ورود و خدمت تصادفی)
به زبان ساده: در دنیای واقعی، زمان رسیدن مشتریها یا مدت خدمت همیشه دقیق نیست – گاهی زود، گاهی دیر! شبیهسازی این “شانسی بودن” رو با اعداد تصادفی تقلید میکنه تا ببینی سیستم چطور کار میکنه.
انواع مدلهای آماری سودمند
۱- سیستمهای صف (Queueing Systems) توضیح تخصصی: زمان بین دو ورود (Interarrival) و زمان خدمتدهی معمولاً تصادفی (مثل توزیع نمایی یا پواسون) هستند. گاهی زمان ورود ثابت است (Deterministic، مثل خط مونتاژ خودرو با سرعت ثابت). به زبان ساده: مثل صف بانک: مشتریها تصادفی میان، خدمت هم طول میکشه متفاوت. اما در کارخانه خودرو، ماشینها با فاصله ثابت روی نوار میآن!
۲- مدلهای مدیریت موجودی (Inventory Management Models) توضیح تخصصی: سه متغیر تصادفی اصلی: مقدار تقاضا در دوره، فاصله بین تقاضاها، و زمان تحویل (Lead Time). در مدلهای ریاضی ساده، تقاضا ثابت و تحویل فوری است؛ اما در شبیهسازی پیشرفته، همه تصادفی برای واقعیتر کردن (مثل مدل (s, S) یا EOQ با عدم قطعیت). به زبان ساده: در فروشگاه: نمیدونی دقیق چند نفر چی میخوان، کی سفارش میدن، یا سفارش کی میرسه! شبیهسازی کمک میکنه موجودی رو طوری تنظیم کنی که نه کم بیاد، نه زیاد بمونه و ضرر کنی.

(تصاویر بالا: دیاگرام مدل شبیهسازی مدیریت موجودی)
۳- مدلهای پایانی (Reliability / Breakdown Models) توضیح تخصصی: مدلهایی برای خرابی ماشینآلات (Machine Failure) با توزیع زمان تا خرابی (MTTF) و زمان تعمیر (MTTR)، اغلب نمایی یا ویبول. به زبان ساده: یعنی مدلهایی که میگن “ماشین تولید ممکنه یهو خراب بشه و کار وایسه”، پس باید موجودی قطعات یدکی و برنامه تعمیر رو طوری تنظیم کنی که کارخانه ضرر نکنه – دقیقاً مثل دنیای واقعی کارخانهها که ماشینها ناگهانی از کار میافتن!
تصور کن یک ماشین یا قطعه داری که کار میکنه تا یه روزی خراب بشه. این “زمان تا خرابی” رو در مدلهای شبیهسازی باید پیشبینی کنیم.
در مدلهای پیشرفته موجودی (مثل انبار قطعات یدکی برای تعمیر ماشینها)، این زمان رو با الگوهای مختلف شبیهسازی میکنن – سادهترین و رایجترینش الگوی نمایی هست: یعنی ماشین ممکنه زود خراب بشه، یا خیلی طولانی کار کنه، اما شانس خرابی همیشه ثابته (مثل لامپ که هر لحظه ممکنه بسوزه، مهم نیست چقدر کار کرده).
اگر فقط این زمان خرابی تصادفی باشه (و بقیه چیزها منظم)، بهترین و سادهترین راه اینه که بگیم از الگوی نمایی استفاده کن – چون واقعیتره و محاسبات راحتتر میشه.

(تصاویر بالا: دیاگرام مدل خرابی ماشین و قابلیت اطمینان در شبیهسازی)
توزیعهای گسسته (Discrete Distributions)
توزیعهای گسسته برای مدلسازی متغیرهای تصادفی که فقط مقادیر صحیح (Integer) میگیرند، استفاده میشوند (بر اساس منابع معتبر مانند کتاب «احتمال و آمار مهندسی» والپول و مایرز، Khan Academy، StatLect و کتاب شبیهسازی بنکس و کارسن ترجمه محلوجی).
(تصاویر بالا: گرافهای PMF توزیعهای گسسته معروف مانند برنولی، دوجملهای و پواسون)
۱- آزمایشهای برنولی و توزیع برنولی (Bernoulli Distribution)
توضیح تخصصی: آزمایش برنولی (Bernoulli Trial)، آزمایشی با فقط دو نتیجه ممکن است: موفقیت (Success) با احتمال p و شکست (Failure) با احتمال ۱-p. متغیر تصادفی X_j برای j-امین آزمایش برنولی تعریف میشود:
- Xj = ۱ اگر موفقیت (با احتمال p)
- Xj = ۰ اگر شکست (با احتمال q = ۱-p)
میانگین (امید ریاضی):
E(Xj)=۱⋅p+۰⋅(۱−p)=p
واریانس:
Var(Xj)=E(Xj2)−[E(Xj)]2=p−p2=p(۱−p)
این توزیع پایه توزیعهای دوجملهای (Binomial) و هندسی است و در شبیهسازی برای مدلسازی رویدادهای باینری (بله/خیر) استفاده میشود.
به زبان ساده: آزمایش برنولی مثل پرتاب یک سکه نامتعادل است: فقط دو جواب داره – شیر (موفقیت) یا خط (شکست). اگر شانس شیر p باشه، میانگین نتیجه (امید ریاضی) همون p است – یعنی اگر میلیون بار پرتاب کنی، به طور متوسط p بار شیر میآد. واریانس p(۱-p) نشون میده چقدر نتیجه پراکنده است (حداکثر واریانس وقتی p=۰.۵ باشه، یعنی سکه متعادل و پراکندگی زیاد).
(تصاویر بالا: مثال سکه و گراف PMF توزیع برنولی)
مثال واقعی و ساده
فرض کن در یک خط تولید، احتمال اینکه یک قطعه معیوب باشه p = ۰.۰۵ (۵%) باشه.
- X_j = ۱ اگر قطعه j معیوب باشه (موفقیت در تشخیص عیب!).
- X_j = ۰ اگر سالم باشه.
میانگین: E(X_j) = ۰.۰۵ → به طور متوسط از هر ۱۰۰ قطعه، ۵ تا معیوب انتظار داریم. واریانس: Var(X_j) = ۰.۰۵ × ۰.۹۵ = ۰.۰۴۷۵ → انحراف معیار ≈ ۰.۲۱۸ (پراکندگی کم، چون احتمال عیب کمه).
یا مثال سکه: اگر سکه نامتعادل باشه و p(شیر)=۰.۷، میانگین ۰.۷ و واریانس ۰.۷×۰.۳=۰.۲۱ – نتیجه بیشتر شیر میشه، اما هنوز کمی پراکندگی داره!
این توزیع در شبیهسازی صف، موجودی و خرابیها خیلی کاربرد داره چون خیلی از رویدادها “اتفاق افتاد/نیفتاد” هستن.
توزیع دوجملهای (Binomial Distribution)
توضیح تخصصی
متغیر تصادفی X که تعداد موفقیتها در n آزمایش مستقل برنولی (هر کدام با احتمال موفقیت ثابت p) است، توزیع دوجملهای (Binomial) با پارامترهای n و p دارد. تابع جرم احتمال (PMF) آن به صورت زیر است (بر اساس منابع معتبر مانند کتاب والپول و مایرز، Wikipedia و Statology):
P(X=k)=(kn)pk(1−p)n−k
که در آن
(kn)=k!(n−k)!n!
ضریب 2 جمله ای است.
میانگین: E(X) = np واریانس: Var(X) = np(۱-p)
این توزیع در کنترل کیفیت، نظرسنجیها و شبیهسازی رویدادهای تکراری موفقیت/شکست کاربرد گسترده دارد.

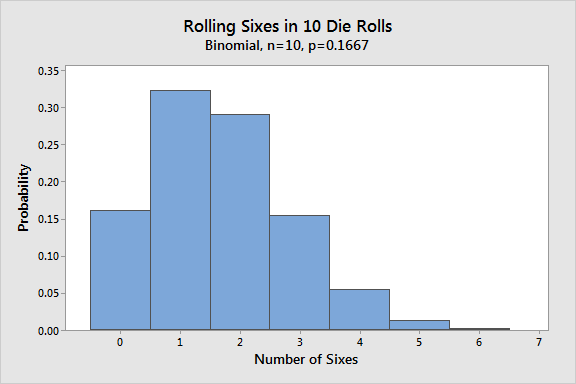
(تصاویر بالا: گراف PMF توزیع دوجملهای و فرمول احتمال)
به زبان ساده: دوجملهای مثل شمردن تعداد “شیر” در n بار پرتاب سکه است. هر پرتاب مستقل و شانس موفقیت (p) ثابته. احتمال دقیق k موفقیت رو با این فرمول حساب میکنیم – مثل ترکیب انتخاب k تا از n تا!
مثال: کنترل کیفیت لامپ در کارخانه
توضیح تخصصی: فرض کنید نسبت متوسط نقص لامپ p = ۰.۰۲ (۲%)، نمونه روزانه n = ۵۰ لامپ تصادفی. اگر تعداد نقص > ۲ (یعنی بیش از ۲ لامپ معیوب، چون ۲/۵۰ = ۰.۰۴ = ۴% > ۲%)، فرایند متوقف میشود.
X ~ Binomial(n=۵۰, p=۰.۰۲) احتمال متوقف کردن=
P(X > ۲) = ۱ – P(X ≤ ۲) = ۱ – [P(X=۰) + P(X=۱) + P(X=۲)]
محاسبه دقیق (با جدول یا نرمافزار):
P(X=۰) ≈ ۰.۳۶۴۲ P(X=۱) ≈ ۰.۳۷۱۶ P(X=۲) ≈ ۰.۱۸۵۸
جمع
P(X ≤ ۲) ≈ ۰.۹۲۱۶ ≈ ۰.۰۷۸۴ (۷.۸۴%)
(اگر “بیش از ۲ درصد” یعنی بیش از ۱ لامپ (چون ۱/۵۰=۲%، بیش از ۲% یعنی ≥۲)، احتمال بالاتر میشود، اما بر اساس متن “بیش از ۲ درصد” معمولاً >۲ لامپ است.)
(تصاویر بالا: مثال کنترل کیفیت کارخانه با توزیع دوجملهای)
به زبان ساده: در کارخانه لامپ، هر لامپ ۲% شانس معیوب بودن داره. از ۵۰ تا نمونه میگیریم: اگر بیشتر از ۲ تا معیوب باشه (بیش از ۴% نمونه)، خط تولید رو خاموش میکنیم. احتمال اینکه این اتفاق بیفته و خط متوقف بشه، حدود ۸% است – یعنی بیشتر روزها خط کار میکنه، اما گاهی چک میکنه و مشکل رو پیدا میکنه!
میانگین و واریانس توزیع ۲ جمله ای را حساب کنید.
برای توزیع دوجملهای با n آزمایش و p احتمال موفقیت میگیم که:
miyangin μ = n p، Var σ² = n p (۱-p)
مدت های احتمالی بین ۲ ورود را بیان کنید:
مثلاً تو صف بانک، مدت بین دو ورود مشتریها میتونه توزیع نمایی (exponential) با میانگین ۵ دقیقه باشه، یعنی احتمال ورود بعدی رندومه و به زمان قبلی بستگی نداره.
غیر از ۳ مدل آماری سودمند، مدل های آماری سودمند درمورد داده های محدود وجود داره؟
آره : زنجیرههای مارکوف( برای فرآیندهای تصادفی محدود)، شبکههای صف( برای سیستمهای پیچیده)، شبیهسازی مونت کارلو( برای تخمین با داده کم)، مدلهای پایایی پیشرفته و مدلهای موجودی با تقاضای .
یادآوری ترکیب و فاکتوریل
۲ از ۳: ۳ میشن یعنی ۳ فاکتوریل بر روی ۲ فاکتوریل
۴ از ۷: ۳۵ یعنی ۷ فاکتوریل بر روی ۴ فاکتوریل
۵ فاکتوریل: ۱۲۰
۷ فاکتوریل / ۴ فاکتوریل: ۲۱۰
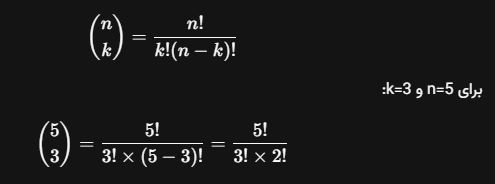
توزیع هندسی
توزیع هندسی، یک توزیع احتمال گسسته است که تعداد آزمایشهای برنولی مستقل (با احتمال موفقیت ثابت p و شکست q = 1 – p) تا رسیدن به اولین موفقیت را مدل میکند.
متغیر تصادفی X ~ Geometric(p) معمولاً به صورت تعداد آزمایشها تا اولین موفقیت تعریف میشه (این تعریف استاندارد در بیشتر منابع مثل Wikipedia و Cuemath هست).

این فرمولها در منابع معتبر مثل StatLect، GeeksforGeeks و کتابهای استاندارد آمار (مثل Introduction to Probability از Blitzstein) تأیید شدن. نکته: گاهی تعریف دیگهای وجود داره که X تعداد شکستها قبل از اولین موفقیت باشه (شروع از 0)، که در اون صورت E(X) = q/p و Var(X) = q/p² میشه – اما تعریف تو و استاندارد رایج در احتمالات مدرن، همون تعداد آزمایشهاست.
توزیع هندسی خاصه توزیع منفی دوجملهای (Negative Binomial) هست وقتی تعداد موفقیتهای مورد نیاز r=1 باشه.
توضیح به زبان ساده:
دوست من، توزیع هندسی مثل اینه که یه آزمایش رو (مثل پرتاب سکه، که شیر موفقیت باشه با احتمال p=0.5) هی تکرار کنی تا بالاخره اولین موفقیت رو ببینی. X نشون میده چند تا پرتاب لازم داری تا اولین شیر بیاد.
مثال کلاسیک: پرتاب سکه عادل تا اولین شیر – میانگیناً ۲ بار پرتاب لازم داری (چون ۱/۰.۵=۲)، اما ممکنه ۱ بار، یا ۱۰ بار هم بشه!
یا مثلاً: فروشندهای که تلفن میزنه تا اولین فروش رو بکنه، یا بازیکنی که تیراندازی میکنه تا اولین گل بزنه.
احتمال اینکه دقیقاً در آزمایش x-ام موفق بشی: اول x-1 بار شکست بخوری، بعد موفق بشی.
این توزیع همیشه راستکج (right-skewed) هست، یعنی دم بلند به سمت راست داره – چون گاهی خیلی طول میکشه!
اینجا چند تصویر عالی از منابع معتبر (مثل Statistics By Jim، GeeksforGeeks و ResearchGate) برات آوردم که تابع جرم احتمال (PMF) رو برای pهای مختلف نشون میدن – ببین چقدر واضحه که با کوچیک شدن p، توزیع کشیدهتر میشه:
و اینا مثالهای تصویری با پرتاب سکه (coin toss) که دقیقاً نشون میده چطور کار میکنه:
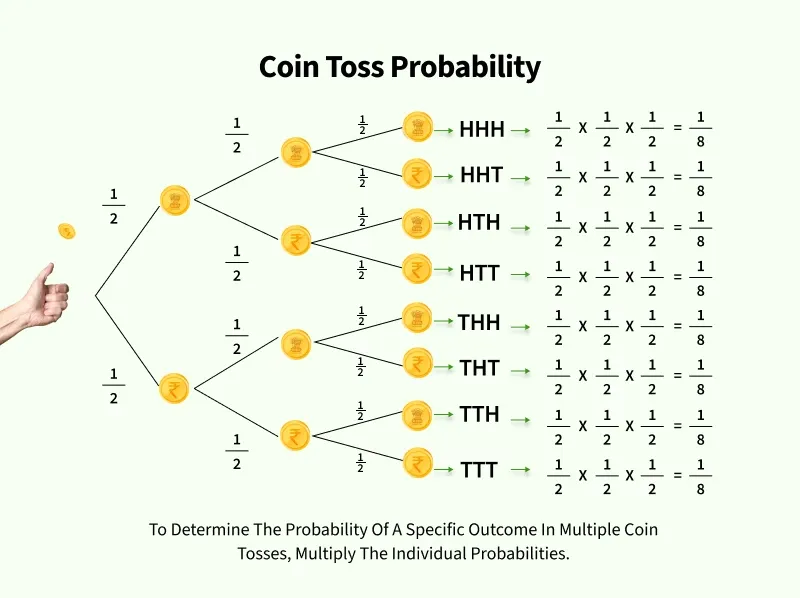

توزیع پواسون
توزیع پواسون یک توزیع احتمال گسسته است که تعداد وقوع یک پیشامد نادر (rare events) در یک بازه زمانی یا مکانی ثابت را مدل میکند، وقتی که این وقوعها مستقل باشند و با نرخ ثابت λ (لاندا > ۰) اتفاق بیفتند. این توزیع از فرآیند پواسون (Poisson Process) میآید که ویژگیهایش شامل استقلال وقوعها و نرخ ثابت است.

توضیح به زبان ساده:
دوست من، توزیع پواسون مثل اینه که بخوای بشماری چند تا اتفاق “نادر و تصادفی” در یه زمان ثابت میافته – مثلاً چند تا تماس تلفنی در یه ساعت به یه مرکز میرسه، یا چند تا خرابی ماشین در یه خط تولید، یا حتی چند تا گل در یه مسابقه فوتبال!
مهمترین ویژگیش اینه که میانگین تعداد اتفاقها (λ) با واریانسش یکی هست – یعنی پراکندگی دور میانگین هم به اندازه خود میانگینه.
در مثال تو: دستگاه ضبط پیام مخابرات به طور میانگین ۲ بوق (یا تماس) در ساعت میگیره. احتمال اینکه دقیقاً ۳ تا بوق در یه ساعت بشنوی، حدود ۱۸٪ هست – نه خیلی زیاد، نه خیلی کم، چون نزدیک میانگینه.
این توزیع خیلی واقعی کار میکنه برای چیزهایی که “نادر” اما ممکنن، مثل رسیدن مشتری به مغازه یا اشتباه تایپی در یه صفحه کتاب.
اینجا چند تصویر عالی از منابع معتبر (مثل Wikipedia، GeeksforGeeks، NIST و Statistics How To) برات آوردم که گراف تابع جرم احتمال (PMF) رو برای λهای مختلف نشون میدن – ببین چقدر قشنگ وقتی λ کوچیکه کجه و وقتی بزرگ میشه شبیه نرمال میشه:


توزیعهای پیوسته (Continuous Probability Distributions)
متغیر تصادفی پیوسته X میتونه هر مقدار واقعی در یک بازه بگیره. به جای تابع جرم احتمال (PMF)، از تابع چگالی احتمال (PDF) به نام f(x) و تابع توزیع تجمعی (CDF) به نام F(x) = P(X ≤ x) استفاده میشه.
احتمال در یک نقطه همیشه صفره (چون بینهایت نقطه وجود داره)، اما احتمال در بازه [x1, x2] برابر انتگرال PDF در اون بازهست:

توزیع نمایی (Exponential): X ~ Exp(λ) (نرخ λ > ۰)

توضیح به زبان ساده:
دوست من، توزیع پیوسته مثل اینه که متغیر میتونه “هر عددی” در یک محدوده بگیره، نه فقط اعداد خاص. مثلاً زمان رسیدن اتوبوس، یا وزن یک سیب – نمیتونی بگی دقیقاً ۱۰۰.۰۰۰ گرم، بلکه هر چیزی ممکنه.
- یکنواخت: همه مقادیر در بازه [a,b] شانس برابر دارن. مثل انتخاب تصادفی یک نقطه روی یک خط مستقیم – مثلاً زمان رسیدن اتوبوس اگر均匀 بین ۰ تا ۱۰ دقیقه باشه.
- نرمال: معروف به “زنگولهای” – بیشتر مقادیر دور میانگین جمع میشن، و دمها کماحتمال. مثلاً قد آدمها در یک جمعیت، یا نمرات آزمون استاندارد.
- نمایی: برای “زمان انتظار” تا یک اتفاق – مثلاً چقدر طول میکشه تا لامپ بسوزه، یا مشتری بعدی بیاد.
اینجا چند تصویر عالی از منابع معتبر برات آوردم که گرافهای PDF و CDF رو برای این توزیعها نشون میدن – اول یکنواخت، بعد نرمال، نمایی، و مقایسه کلی:
توزیع نمایی
توزیع نمایی یک توزیع احتمال پیوسته است که زمان بین وقوعهای متوالی در یک فرآیند پواسون (با نرخ λ > ۰) را مدل میکند. متغیر تصادفی X ≥ ۰ هست و پارامتر λ نرخ (rate) هست.

مثال عملی:
فرض کن یک مرکز تماس تلفنی به طور میانگین λ = ۵ تماس در ساعت دریافت میکنه (فرآیند پواسون). زمان بین دو تماس متوالی X ~ Exp(۵).
- میانگین زمان انتظار: ۱/۵ = ۰.۲ ساعت (۱۲ دقیقه).
- احتمال اینکه زمان بین دو تماس کمتر از ۱۰ دقیقه (۰.۱۶۷ ساعت) باشه: F(۰.۱۶۷) = ۱ – e^{-۵×۰.۱۶۷} ≈ ۰.۵۷ (۵۷٪).
توضیح به زبان ساده:
دوست من، توزیع نمایی مثل اینه که بخوای “چقدر طول میکشه تا اتفاق بعدی بیفته” رو مدل کنی – مثلاً چقدر صبر کنی تا اتوبوس بعدی بیاد (اگر اتوبوسها تصادفی و با نرخ ثابت بیان)، یا چقدر طول میکشه تا مشتری بعدی وارد مغازه بشه، یا حتی زمان خدمت یک اپراتور که خیلی متغیره.
ویژگی “بدون حافظه”ش فوقالعادهست: اگر ۱۰ دقیقه صبر کردی و اتوبوس نیومده، احتمال اینکه ۵ دقیقه دیگه هم صبر کنی، همونه که از اول ۵ دقیقه صبر کنی – انگار “یادش نمیمونه” چقدر صبر کردی!
گرافش همیشه از بالا شروع میشه و به سمت راست کمکم پایین میآد (راستکج)، و با بزرگ شدن λ، سریعتر پایین میآد (یعنی زمانهای کوتاهتر محتملترن).
توزیع گاما

مثال ساده:
فرض کن در یک مرکز خدمات، زمان خدمت هر مشتری توزیع نمایی با نرخ β = ۳ (میانگین ۱/۳ ساعت) داره. زمان کل خدمت به دقیقاً ۵ مشتری متوالی (بدون وقفه) X ~ Gamma(α=۵, β=۳).
- میانگین زمان کل: ۵/۳ ≈ ۱.۶۷ ساعت
- این دقیقاً توزیع ارلنگه و نشون میده چقدر طول میکشه تا ۵ مشتری خدمت بشن.
توضیح به زبان ساده:
دوست من، توزیع گاما مثل اینه که بخوای مجموع زمانهای چند تا اتفاق نمایی (مستقل) رو مدل کنی – مثلاً چقدر طول میکشه تا ۴ تا مشتری پشت سر هم خدمت بشن، یا زمان کل بارندگی در چند روز، یا عمر یک سیستم که از چند قطعه تشکیل شده.
وقتی α کوچیکه (مثل ۱)، شبیه نماییه و راستکجه، اما با بزرگ شدن α، بیشتر شبیه زنگولهای (نرمال) میشه. پارامتر α نشون میده “چند تا” مرحله داری، و β سرعت هر مرحلهست.
اینجا چند تصویر عالی از منابع معتبر برات آوردم که گرافهای PDF توزیع گاما رو برای پارامترهای مختلف نشون میدن – ببین چقدر قشنگ شکلش تغییر میکنه:
توزیع ارلنگ
توزیع ارلنگ مورد خاص توزیع گاما است وقتی پارامتر شکل α = k (عدد صحیح مثبت) و پارامتر نرخ β (یا گاهی λ) باشه. PDF آن:


در مثال لامپ: هر لامپ به طور میانگین ۱۰۰۰ ساعت کار میکنه، اما با دو تا پشتیبان، احتمال اینکه کل سیستم بیشتر از ۲۱۶۰ ساعت (۹۰ روز) دوام بیاره حدود ۳۶.۵٪ هست – یعنی شانس خوبی داری وقتی برگردی هنوز روشن باشه! اگر فقط یک لامپ بود، شانس فقط ۱۱٪ بود.



